반응형

이 강좌는 MySQL 데이터베이스를 처음 접하는 분들을 위한 완벽 가이드입니다. 단순한 이론 설명 대신, 웹사이트에서 직접 코드를 입력하고 결과를 확인하며 데이터를 배우는 실용적인 접근 방식을 제공합니다. 데이터를 조회하고, 원하는 조건으로 필터링하며, 여러 테이블을 조인하여 복잡한 정보를 추출하는 핵심 SQL 문법을 익힐 수 있습니다. 또한, 직접 데이터베이스를 설치하고 테이블을 생성, 수정, 삭제하는 방법을 배우며 실제 개발 환경에서 MySQL을 활용하는 능력을 키울 수 있습니다.
1. MySQL 강좌 소개 및 학습 목표
- 강좌의 목적: 프로그래밍 경험이 있거나 SQL을 다루는 사람들을 위해 MySQL을 쉽게 배울 수 있도록 기획되었다.
- 학습 방식: 어려운 이론이나 복잡한 기술 설명은 최소화하고, 컴퓨터에 별도 설치 없이 웹사이트에서 코드를 입력하며 MySQL을 '놀듯이' 배울 수 있도록 구성되었다.
- 강좌의 목표: 공부를 또 다른 즐거움으로 받아들이는 것이 목표이다.
2. 강좌 커리큘럼 및 구성
- 챕터 구성: '하와이', '기차', '버거', '치킨', '20년'이라는 챕터로 구성되어 있다.
- 챕터 1-3 (기초 및 핵심 문법)
- MySQL의 기초와 핵심 문법을 다룬다.
- 테이블 생성, 함수 등 데이터를 다루는 기본적인 방법을 포함한다.
- 누구나 쉽게 이해할 수 있도록 구성되었으며, 유튜브에서 무료로 수강할 수 있다.
- 챕터 4-5 (심화 및 실전 활용)
- 키 제약, 뷰, 인덱스 등 자세한 주제를 다룬다.
- MySQL을 실전에서 사용하는 방법을 실습을 통해 익힌다.
- MySQL을 사용하여 웹사이트를 제작하고 온라인 서버에 업로드하는 프로세스까지 진행한다.
- 유료 강좌로 제공되며, '치킨 한 마리 가격'으로 수강할 수 있다.
3. 데이터베이스의 기본 개념
- MySQL의 정의: MySQL은 가장 널리 사용되는 RDBMS(관계형 데이터베이스 관리 시스템)이다.
- 데이터베이스의 역할: 한 곳에 저장된 정보들을 특정 소프트웨어나 프로그램에 종속되지 않고 어디서든 사용할 수 있는 독립된 정보 집합 또는 저장소이다.
- DBMS(데이터베이스 관리 시스템)
- 데이터베이스에 정보를 집어넣고 원하는 것을 찾는 등의 각종 기능을 자판기처럼 만들면 DBMS가 된다.
- 하나의 소프트웨어로 볼 수 있다.
- 데이터 관리 방식: 각 데이터베이스는 사용자가 정보를 입력, 조회, 수정, 삭제하는 등 데이터를 관리할 수 있는 방식을 제공한다.
- SQL(Structured Query Language)
- MySQL을 비롯한 다수의 데이터베이스는 SQL을 데이터 관리 방식으로 사용한다.
- SQL은 '식권'처럼 편하게 발음하기도 한다.
- SQL은 도메인 특화 언어(Domain Specific Language)에 가깝다.
- 개발자가 아닌 사람들에게는 어려워 보일 수 있지만, 그대로 읽기만 하면 되는 단순한 명령문이다.
4. MySQL의 데이터 저장 방식
- 파일 문서 저장 방식 (비관계형 데이터베이스)
- 정보를 각 파일 문서로 저장하는 방법도 있다 (예: 몽고DB).
- 장점: 데이터 입력이 자유롭고 읽기 속도가 빠르다.
- 단점: 데이터마다 일정한 형태를 가져야 소프트웨어들이 안정적으로 사용할 수 있는데, 제약이 없는 방식은 항목 누락, 이름 불일치, 데이터 형식 상이 등으로 다양한 오류가 발생할 수 있다.
- 표 형태 저장 방식 (관계형 데이터베이스)
- MySQL과 같은 종류의 데이터베이스는 표와 비슷한 방식으로 데이터를 저장한다.
- 구조: 각 컬럼(열)마다 이름이 있고, 이 칸들이 모여 행을 이루며, 행들이 모여 표를 만든다.
- 특징: 각 컬럼에는 이름뿐만 아니라 들어갈 수 있는 데이터의 형태가 지정되어 있어 정보 입력 방식을 한정할 수 있다.
- 장점: 데이터의 일관성을 유지할 수 있다.
- SQL의 역할: 이와 같은 표 형태의 데이터베이스에 정보를 넣고 빼고 수정하고 사용하는 데 사용되는 것이 SQL이다.
- SQL 명령문 예시: 푸드코트 테이블에서 '가격'이 7000원인 메뉴의 '푸드 이름', '업체명', '메뉴 이름', '가격' 컬럼을 가져오는 명령문은 SELECT 푸드이름, 업체명, 메뉴이름, 가격 FROM 푸드코트테이블 WHERE 가격 = 7000;과 같다.
- 관계형 데이터베이스의 특징: 정보를 나눌 수 있고, SQL이라는 버튼을 제공하여 원하는 대로 정보를 넣고 뺄 수 있으며, 데이터의 일관성이 지켜지는 데이터베이스 시스템이다.
5. 관계형 데이터베이스의 효율성: 테이블 분리 및 조인
- 테이블 분리의 필요성: 표 형태의 데이터는 데이터의 일관성을 보장하지만, 중복된 데이터로 인해 비효율적인 부분이 발생할 수 있다.
- 예시: '분식' 코너가 2층에 있다는 정보가 여러 행에서 중복되거나, '달다방'이 오픈 상태이고 배달 가능하다는 정보가 여러 행에서 중복되는 경우.
- 문제점: 중복된 정보를 수정할 때 여러 곳을 일일이 찾아 바꿔야 하는 비효율성과 오류 발생 가능성이 높다.
- 테이블 분리 방법: 하나의 큰 테이블을 '코너 섹션 테이블', '식당 비즈니스 테이블', '메뉴 메뉴 테이블' 등으로 적절히 분리하여 중복을 제거한다.
- 테이블 간 관계 설정: 분리된 테이블들은 서로 관계를 맺어줌으로써 필요한 정보를 다시 연결할 수 있다.
- 고유 ID (Primary Key): 각 테이블의 행마다 주민번호처럼 고유한 ID 값을 부여한다 (예: 코너 테이블의 ID).
- 외래 키 (Foreign Key): 다른 테이블의 고유 ID를 참조하는 컬럼을 만들어 테이블 간의 관계를 설정한다 (예: 식당 테이블에 코너 ID를 넣어 해당 식당이 어떤 코너에 속하는지 연결).
- 조인(JOIN) 기능: MySQL과 같은 관계형 데이터베이스는 분리된 여러 테이블을 다시 합쳐서 조회할 수 있는 '조인' 기능을 제공한다.
- SQL 명령: SELECT ... FROM 코너테이블 JOIN 식당테이블 ON 코너테이블.ID = 식당테이블.코너ID JOIN 메뉴테이블 ON 식당테이블.ID = 메뉴테이블.식당ID;와 같은 명령으로 실행할 수 있다.
- 결과: 여러 테이블에 분산된 데이터를 하나의 테이블에서 보는 것처럼 확인할 수 있다.
- 관계형 데이터베이스의 강력함: 조인 외에도 데이터를 필터링, 정렬, 가공하여 의미 있는 정보를 만들어내는 다양하고 강력한 기능들을 제공한다.
- 관계형 데이터베이스의 종류: MySQL을 비롯하여 오라클, MSSQL, PostgreSQL 등 오랫동안 널리 사용되어 온 데이터베이스들은 관계형 데이터베이스에 속한다.
- SQL 데이터베이스: 관계형 데이터베이스들은 공통적으로 SQL을 사용하여 데이터를 관리하므로 'SQL 데이터베이스'라고도 불린다.
6. 비관계형 데이터베이스 (NoSQL)
- 정의: 관계형이 아닌 데이터베이스들을 '비관계형 데이터베이스' 또는 'NoSQL 데이터베이스'라고 부른다.
- 종류: 몽고DB, 카산드라, 다이나모DB, 레디스 등 무수히 많다.
- 특징: 각각의 데이터베이스마다 방식이 다르다.
- 명칭: NoSQL은 'Not only SQL'의 약자이지만, 'No SQL'로 알고 있어도 무방하다.
7. MySQL의 장점 및 활용
- 경제성 및 선호도: MySQL은 무료 또는 저렴한 가격에 사용 가능하며 선호도가 높아, 관계형 DB 중 오라클과 더불어 가장 널리 사용된다.
- 사용처: 규모가 있는 기업에서는 오라클을, 작은 규모나 개인 용도로는 MySQL을 많이 사용한다.
- 학습의 확장성: 관계형 데이터베이스들마다 SQL 언어는 세부 기능을 제외하고는 거의 비슷하므로, MySQL을 배우면 오라클, PostgreSQL 등 다른 데이터베이스도 쉽게 익힐 수 있다.
8. 강좌 학습 가이드 및 실습 환경
- 강의 특징: 수강자의 시간을 소중히 여겨 핵심 내용으로 꽉 찬 강의를 진행한다.
- 보조 교재 활용: 강좌 웹사이트를 보조 교재로 활용하여 복잡하지 않은 예제 코드를 직접 사용해 보며 MySQL 스킬을 공부할 수 있다.
- 효율적인 학습 방법: 강의 영상을 한 번 본 후, 웹사이트를 보고 예제를 직접 입력해 보면서 수업을 진행하는 것이 좋다.
- 실습의 중요성: 단순히 강의 내용을 따라 하는 것을 넘어, 다양한 시도를 해보고 데이터를 '갖고 놀듯이' 실습해야 MySQL을 능숙하게 다룰 수 있다.
- 타이핑 연습: 강의에서는 복사-붙여넣기를 사용하지만, 학습자는 직접 타이핑하여 명령어에 익숙해지는 것이 중요하다.
- 다양한 적용: 배운 기능을 다른 테이블이나 다른 조건에도 이리저리 시험해 보면서 머리와 손으로 MySQL을 익혀야 한다.
9. MySQL 워크벤치 실습 시작
- 접속: 강의 웹사이트에 접속하여 챕터 1의 첫 섹션 '기능 훑어보기'를 시작한다.
- W3Schools 샘플 DB: W3Schools에서 제공하는 샘플 데이터베이스를 활용한다.
- 이 샘플 DB는 상품을 파는 회사들이 고객들을 고용하는 정보가 담겨 있다.
- 학습자는 여기에 직접 코드를 입력하여 MySQL의 다양한 기능을 연습하고 테스트할 수 있다.
- 실습 환경: 챕터 1과 2에서는 별도의 콘텐츠 없이 모든 강의 상단에 있는 실습 링크를 통해 웹페이지에서 MySQL 조회 기능을 실습한다.
- 조회 기능은 정보를 입력, 수정, 삭제하는 것이 아니라, 원하는 정보를 가져와서 보는 기능이다.
10. SELECT 문 기본 사용법
10.1. 모든 컬럼 조회
- SELECT <em> FROM 테이블명;: </em>는 테이블의 모든 컬럼을 의미한다.
- 예시: SELECT * FROM Customers;를 실행하면 Customers 테이블의 모든 컬럼이 조회된다.
- 주석(Comment)
- 목적: 컴퓨터는 실행하지 않고 사람이 알아볼 수 있도록 코드에 설명을 추가하는 기능이다.
- 필요성: 긴 코드에서 특정 부분이 어떤 역할을 하는지 빠르게 파악하거나, 다른 사람이 코드를 이해하는 데 도움을 준다.
- 문법: MySQL에서는 -- (하이픈 두 개와 한 칸 띄어쓰기)를 사용하여 주석을 단다.
10.2. 특정 컬럼 선택 조회
- SELECT 컬럼명1, 컬럼명2 FROM 테이블명;: 원하는 컬럼만 선택하여 조회할 수 있다.
- 예시: SELECT CustomerName FROM Customers;를 실행하면 CustomerName 컬럼만 조회된다.
- 여러 컬럼을 선택할 때는 쉼표(,)로 구분한다.
10.3. 컬럼이 아닌 값 출력
- SELECT 컬럼명, 값1, 값2 FROM 테이블명;: 테이블의 컬럼 외에 숫자, 문자열, NULL 값 등도 함께 출력할 수 있다.
- 예시: SELECT CustomerName, 1, 'Hello', NULL FROM Customers;를 실행하면 CustomerName과 함께 숫자 1, 문자열 'Hello', NULL 값이 각 행에 출력된다.
- 문자열 표기: 문자열은 작은따옴표(')로 묶어야 한다.
- 컬럼명은 따옴표 없이 사용하면 컴퓨터가 컬럼 이름으로 인식한다.
- 숫자는 따옴표 없이 사용하면 컴퓨터가 숫자로 인식한다.
- 따옴표 없이 문자열을 입력하면 컴퓨터가 어떤 정보인지 알 수 없어 오류가 발생한다.
- NULL: NULL은 '비어 있음'을 의미하며, 아무것도 출력되지 않는다.
11. WHERE 절을 이용한 조건 필터링
- SELECT * FROM 테이블명 WHERE 조건;: WHERE 절을 사용하여 특정 조건을 만족하는 행(레코드)만 선택하여 가져올 수 있다.
- 조건 지정: WHERE 뒤에 조건을 명시한다.
- 예시: SELECT * FROM Orders WHERE EmployeeID = 3;를 실행하면 EmployeeID가 3인 주문 정보만 조회된다.
- 다양한 조건 활용: WHERE 절은 이후 챕터에서 더 자세히 다룬다.
- SELECT와 WHERE 조합: SELECT 절에서 특정 컬럼을 선택하고 WHERE 절로 조건을 필터링하는 것을 함께 사용할 수 있다.
- 예시: SELECT CustomerID, EmployeeID FROM Orders WHERE EmployeeID = 3;를 실행하면 CustomerID와 EmployeeID만 조회되며, EmployeeID가 3인 행만 필터링된다.
- 숫자 비교: WHERE 절에서 수량(Quantity)과 같은 숫자 컬럼을 비교하여 필터링할 수 있다.
- 예시: SELECT * FROM OrderDetails WHERE Quantity < 5;를 실행하면 Quantity가 5보다 작은 주문 상세 정보만 조회된다.
12. SQL 문법 규칙 및 가독성
- 줄바꿈 및 들여쓰기: SQL 명령어는 줄바꿈, 들여쓰기, 공백 등에 영향을 받지 않는다.
- 단, 단어들은 스페이스, 엔터, 탭 등으로 띄워 주어야 한다.
- 가독성을 위해 특정 길이가 넘어가면 줄바꿈을 하거나 들여쓰기를 하는 것이 좋다.
- 대소문자 구분: MySQL 명령어(예: SELECT, FROM, WHERE)는 대소문자를 구분하지 않는다.
- 일반적으로 가독성을 위해 대문자로 작성하는 경우가 많다.
13. ORDER BY 절을 이용한 정렬
- SELECT * FROM 테이블명 ORDER BY 컬럼명 [ASC|DESC];: ORDER BY 절을 사용하여 조회 결과를 특정 컬럼을 기준으로 정렬할 수 있다.
- 정렬 방식:
- ASC (Ascending): 오름차순 정렬 (기본값).
- DESC (Descending): 내림차순 정렬.
- 단일 컬럼 정렬:
- 예시: SELECT * FROM Customers ORDER BY ContactName ASC;를 실행하면 ContactName을 기준으로 오름차순 정렬된다.
- ASC는 기본값이므로 생략 가능하다.
- 복수 컬럼 정렬: 여러 컬럼을 기준으로 정렬할 수 있으며, 먼저 지정된 컬럼이 우선순위를 가진다.
- 예시: SELECT * FROM OrderDetails ORDER BY ProductID ASC, Quantity DESC;를 실행하면 ProductID로 먼저 오름차순 정렬한 후, 같은 ProductID 내에서는 Quantity를 기준으로 내림차순 정렬된다.
14. LIMIT 절을 이용한 결과 개수 제한
- SELECT * FROM 테이블명 LIMIT 개수;: LIMIT 절을 사용하여 조회 결과의 개수를 제한할 수 있다.
- 예시: SELECT * FROM Customers LIMIT 10;를 실행하면 Customers 테이블에서 10개의 행만 조회된다.
- LIMIT 건너뛸_개수, 보여줄_개수;: 두 개의 숫자를 사용하여 특정 개수를 건너뛰고 원하는 개수만큼 조회할 수 있다.
- 첫 번째 숫자는 건너뛸 개수(Offset), 두 번째 숫자는 보여줄 개수(Limit)를 의미한다.
- 예시: SELECT * FROM Customers LIMIT 30, 10;를 실행하면 30개의 행을 건너뛰고 31번째부터 10개의 행(총 31~40번째)이 조회된다.
- 활용: 웹사이트의 페이지네이션(검색 결과나 게시판 글을 페이지로 나누어 보여주는 기능) 구현에 활용된다.
15. AS 키워드를 이용한 컬럼명 변경
- SELECT 컬럼명 AS 새_컬럼명 FROM 테이블명;: AS 키워드를 사용하여 조회 결과의 컬럼 이름을 원하는 대로 변경할 수 있다.
- 예시: SELECT CustomerID AS ID, CustomerName AS Name, Address AS Addr FROM Customers;를 실행하면 CustomerID, CustomerName, Address 컬럼이 각각 ID, Name, Addr로 이름이 변경되어 출력된다.
- 한글 컬럼명: 한글 컬럼명도 사용할 수 있다.
- 예시: SELECT CustomerID AS ID, CustomerName AS 고객명, Address AS 주소 FROM Customers;
- 단, 웹사이트 실습 환경에서는 한글 사용에 제약이 있을 수 있으며, 컴퓨터에 MySQL을 직접 설치한 환경에서 더 많은 기능을 활용할 수 있다.
16. SELECT, WHERE, ORDER BY, LIMIT, AS 조합 실습
- 종합 예시: 오늘 배운 모든 기능을 활용하여 복잡한 쿼리를 작성할 수 있다.
- 예시: SELECT CustomerID AS ID, CustomerName AS 고객명, City AS 도시, Country AS 국가 FROM Customers WHERE City = 'London' OR Country = 'Mexico' ORDER BY CustomerName ASC LIMIT 0, 5;
- 이 쿼리는 Customers 테이블에서 ID, 고객명, 도시, 국가 컬럼을 가져오되, 도시가 'London'이거나 국가가 'Mexico'인 행만 필터링하고, 고객명 기준으로 오름차순 정렬하여 첫 페이지의 5개 행만 가져온다.
- 복습의 중요성: 강의에서 배운 내용을 바탕으로 다른 테이블에 다양한 명령어를 시도해 보면서 기능을 숙달하는 것이 중요하다.
17. MySQL 연산자 (Operators)
17.1. 사칙 연산자
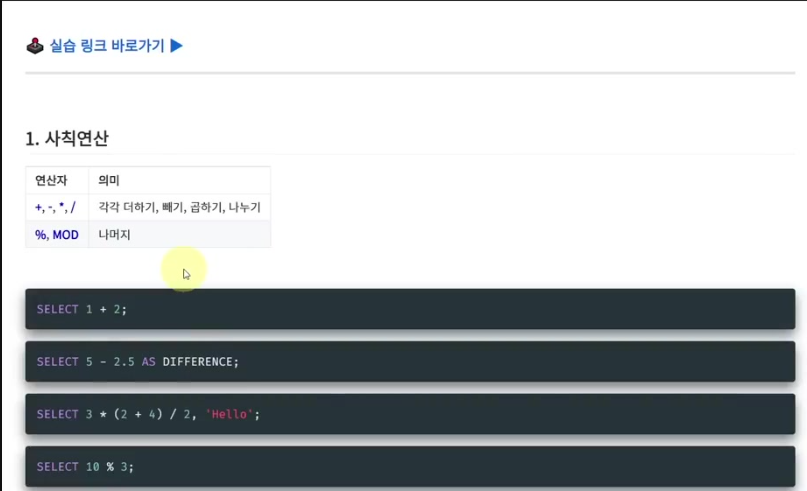
- 종류: + (더하기), - (빼기), * (곱하기), / (나누기), % (나머지 연산)가 있다.
- 테이블 선택 없이 값 출력: SELECT 문으로 특정 테이블을 선택하지 않고도 값을 직접 계산하여 출력할 수 있다.
- 예시: SELECT 1 + 1;을 실행하면 2가 출력된다.
- 컬럼명 지정: AS 키워드를 사용하여 계산 결과에 컬럼명을 지정할 수 있다.
- 예시: SELECT 5 - 2.5 AS Result;를 실행하면 Result라는 컬럼명으로 2.5가 출력된다.
- 괄호 사용: 여러 연산을 섞어 사용할 때 괄호(())를 사용하여 연산 순서를 지정할 수 있다.
- 예시: SELECT (2 + 4) * 3 / 2 AS Number, 'Hello' AS Text;를 실행하면 Number 컬럼에 9, Text 컬럼에 'Hello'가 출력된다.
17.2. 문자열과 숫자 연산의 특징
- 문자열 + 숫자: MySQL에서는 문자열과 숫자를 더하면 문자열을 0으로 인식하여 연산한다.
- 예시: SELECT 'abc' + 3;을 실행하면 3이 출력된다. ('abc'를 0으로 인식)
- 숫자 형태의 문자열 + 숫자: 문자열이라도 그 값이 숫자로 되어 있으면, MySQL은 해당 값을 숫자로 변환하여 연산한다.
- 예시: SELECT '1' + '2000' + 3;을 실행하면 2004가 출력된다. ('1'과 '2000'을 숫자로 인식)
17.3. 테이블 컬럼에 연산자 적용
- 컬럼 간 연산: 테이블의 컬럼들을 대상으로 사칙 연산을 적용할 수 있다.
- 예시: SELECT OrderID, ProductID, OrderID + ProductID AS SumID FROM OrderDetails;를 실행하면 OrderID와 ProductID를 더한 결과가 SumID 컬럼으로 출력된다.
- 문자열 연결: CONCAT 함수를 사용하여 문자열을 연결할 수 있다.
- 예시: SELECT OrderID, ProductID, CONCAT(OrderID, '-', ProductID) AS CombinedID FROM OrderDetails;를 실행하면 OrderID와 ProductID가 하이픈으로 연결된 결과가 CombinedID 컬럼으로 출력된다.
- 컬럼 값 변경: 컬럼의 값을 연산하여 새로운 값을 출력할 수 있다.
- 예시: SELECT ProductName, Price, Price / 2 AS HalfPrice FROM Products;를 실행하면 Price를 2로 나눈 값이 HalfPrice 컬럼으로 출력된다.
- 할인율 적용: Price * 0.75와 같이 곱셈을 사용하여 25% 할인된 가격을 계산할 수 있다.
18. 참/거짓 연산자 (Boolean Operators)
18.1. TRUE/FALSE 및 NOT 연산
- TRUE/FALSE: MySQL에서 TRUE는 숫자 1, FALSE는 숫자 0으로 나타낸다.
- NOT 연산자:
- ! (느낌표): 어떤 값 앞에 붙으면 그 값의 반대(참이면 거짓, 거짓이면 참)를 출력한다.
- 예시: SELECT !TRUE;를 실행하면 0(FALSE)이 출력된다.
- NOT 키워드: NOT 키워드도 동일하게 반대 값을 출력한다. NOT 앞에는 스페이스를 붙여야 한다.
- 예시: SELECT NOT TRUE;를 실행하면 0(FALSE)이 출력된다.
- ! (느낌표): 어떤 값 앞에 붙으면 그 값의 반대(참이면 거짓, 거짓이면 참)를 출력한다.
- 참/거짓 비교:
- 예시: SELECT FALSE = TRUE;를 실행하면 0(FALSE)이 출력된다.
- 예시: SELECT TRUE = TRUE;를 실행하면 1(TRUE)이 출력된다.
- 예시: SELECT FALSE = FALSE;를 실행하면 1(TRUE)이 출력된다.
- 예시: SELECT TRUE = FALSE;를 실행하면 0(FALSE)이 출력된다.
18.2. WHERE 절에서의 참/거짓 활용
- 조건문으로서의 참/거짓: WHERE 절에 TRUE를 붙이면 모든 행이 조회되고, FALSE를 붙이면 아무것도 조회되지 않는다.
- 활용: WHERE 절에 특정 조건을 충족하는 참/거짓 여부를 사용하여 원하는 행을 필터링한다.
- 예시: WHERE City = 'Berlin'과 같은 조건이 참인 행만 출력된다.
18.3. 논리 연산자: AND, OR
- AND 연산자: 양쪽의 조건이 모두 참일 때만 참(TRUE)을 반환한다.
- 예시: SELECT TRUE AND FALSE;를 실행하면 0(FALSE)이 출력된다.
- OR 연산자: 둘 중 하나의 조건이라도 참일 때 참(TRUE)을 반환한다.
- 예시: SELECT TRUE OR FALSE;를 실행하면 1(TRUE)이 출력된다.
- 괄호 사용: AND와 OR를 함께 사용할 때 괄호를 사용하여 연산 순서를 명확히 할 수 있다.
- 예시: SELECT * FROM OrderDetails WHERE ProductID = 20 AND (OrderID = 10250 OR Quantity = 10);를 실행하면 ProductID가 20이고, OrderID가 10250이거나 Quantity가 10인 행이 조회된다.
- WHERE 절에서의 활용: AND와 OR를 WHERE 절에 사용하여 복합적인 조건을 만들 수 있다.
- 예시: SELECT * FROM Orders WHERE CustomerID = 15 AND EmployeeID = 4;를 실행하면 CustomerID가 15이고 EmployeeID가 4인 주문만 조회된다.
- 예시: SELECT * FROM Orders WHERE CustomerID = 15 OR EmployeeID = 4;를 실행하면 CustomerID가 15이거나 EmployeeID가 4인 주문이 조회된다.
19. 비교 연산자
19.1. 숫자 및 문자열 비교
- 종류:
- = (같다)
- <> 또는 != (다르다)
- > (크다)
- < (작다)
- >= (크거나 같다)
- <= (작거나 같다)
- 숫자 비교: 일반적인 수학적 비교와 동일하다.
- 예시: SELECT 1 = 1; (TRUE), SELECT 1 <> 1; (FALSE), SELECT 1 > 1; (FALSE)
- 문자열 비교:
- = (같다): 문자열이 완전히 동일한지 비교한다.
- <> (다르다): 문자열이 다른지 비교한다.
- > 또는 < (크기 비교): 알파벳 순서에 따라 비교한다. 나중에 오는 알파벳이 더 크다.
- 대소문자 구분 안 함: MySQL은 기본적으로 문자열 비교 시 대소문자를 구분하지 않는다.
- 예시: SELECT 'A' = 'a';를 실행하면 1(TRUE)이 출력된다.
19.2. WHERE 절에서의 비교 연산자 활용
- 조건 컬럼 추가: SELECT 절에 비교 연산 결과를 새로운 컬럼으로 추가하여 출력할 수 있다.
- 예시: SELECT ProductName, Price, Price > 20 AS Expensive FROM Products;를 실행하면 Price가 20보다 크면 Expensive 컬럼에 1(TRUE), 아니면 0(FALSE)이 출력된다.
- 활용: WHERE 절에서 특정 조건을 만족하는 행을 필터링하는 데 사용된다.
20. BETWEEN 연산자
- 값 BETWEEN 시작값 AND 끝값: 어떤 값이 특정 범위(시작값과 끝값 포함) 내에 있는지 확인한다.
- 숫자 범위:
- 예시: SELECT 5 BETWEEN 1 AND 10;을 실행하면 1(TRUE)이 출력된다.
- 예시: SELECT 50 BETWEEN 1 AND 10;을 실행하면 0(FALSE)이 출력된다.
- 순서: 항상 작은 숫자가 앞에 와야 한다.
- 문자열 범위: 문자열에도 적용되며, 알파벳 순서에 따라 범위를 판단한다.
- 예시: SELECT 'Banana' BETWEEN 'Apple' AND 'Camera';를 실행하면 1(TRUE)이 출력된다.
- 대소문자 구분 안 함: MySQL은 대소문자를 구분하지 않으므로 'apple'과 'Apple'은 동일하게 취급된다.
- NOT BETWEEN: 특정 범위 내에 있지 않은지 확인한다.
- WHERE 절에서의 활용:
- 예시: SELECT * FROM OrderDetails WHERE ProductID BETWEEN 1 AND 44;를 실행하면 ProductID가 1에서 44 사이에 있는 주문 상세 정보만 조회된다.
- NOT BETWEEN을 사용하면 해당 범위에 없는 행만 조회할 수 있다.
- 문자열 범위 활용: SELECT * FROM Customers WHERE CustomerName BETWEEN 'B' AND 'C';를 실행하면 CustomerName이 'B'로 시작하는 고객만 조회된다.
21. IN 연산자
- 값 IN (값1, 값2, ...): 어떤 값이 괄호 () 안에 나열된 값들 중 하나와 일치하는지 확인한다.
- NOT IN: 괄호 안에 나열된 값들 중 어느 것과도 일치하지 않는지 확인한다.
- 숫자 및 문자열: 숫자와 문자열 모두에 적용 가능하다.
- 예시: SELECT 1 + 2 IN (1, 2, 3, 4);를 실행하면 1(TRUE)이 출력된다. (1+2=3이 괄호 안에 있으므로)
- 예시: SELECT 'Hello' IN (123, TRUE, 'Hello');를 실행하면 1(TRUE)이 출력된다. (MySQL은 대소문자를 구분하지 않으므로)
- WHERE 절에서의 활용:
- 예시: SELECT * FROM Customers WHERE City IN ('Torino', 'Paris', 'Portland', 'Madrid');를 실행하면 City가 'Torino', 'Paris', 'Portland', 'Madrid' 중 하나인 고객만 조회된다.
- NOT IN을 사용하면 해당 도시에 없는 고객만 조회할 수 있다.
22. LIKE 연산자
22.1. LIKE와 % (퍼센트)
- 컬럼명 LIKE '패턴': 문자열이 특정 패턴과 일치하는지 확인한다.
- % (퍼센트): 0개 이상의 어떤 문자열이든 일치한다.
- 예시: 'Hello' LIKE 'H%' (H로 시작하는 모든 문자열) -> TRUE
- 예시: 'Hello' LIKE '%o' (o로 끝나는 모든 문자열) -> TRUE
- 예시: 'Hello' LIKE '%ell%' (ell을 포함하는 모든 문자열) -> TRUE
- 예시: 'Hello' LIKE 'H%o' (H로 시작하고 o로 끝나는 모든 문자열) -> TRUE
- 대소문자 구분 안 함: MySQL은 LIKE 연산 시에도 기본적으로 대소문자를 구분하지 않는다.
- NOT LIKE: 특정 패턴과 일치하지 않는지 확인한다.
- WHERE 절에서의 활용:
- 예시: SELECT * FROM Customers WHERE CustomerName LIKE 'B%';를 실행하면 CustomerName이 'B'로 시작하는 고객만 조회된다.
- 예시: SELECT * FROM Customers WHERE CustomerName LIKE '%s';를 실행하면 CustomerName이 's'로 끝나는 고객만 조회된다.
- 예시: SELECT * FROM Customers WHERE CustomerName LIKE 'An%';를 실행하면 CustomerName이 'An'으로 시작하는 고객만 조회된다.
22.2. LIKE와 _ (언더스코어)
- _ (언더스코어): 정확히 한 개의 문자와 일치한다.
- 예시: 'Hello' LIKE 'H_ll_' (H로 시작하고 두 번째 문자는 아무거나, 세 번째 네 번째는 'll', 다섯 번째는 아무거나) -> TRUE
- 예시: 'Hello' LIKE 'H___o' (H로 시작하고 세 개의 문자가 오고 o로 끝나는) -> TRUE
- 개수 일치: 언더스코어의 개수가 정확히 일치해야 한다.
- WHERE 절에서의 활용:
- 예시: SELECT * FROM Employees WHERE Notes LIKE '%Economist%';를 실행하면 Notes 컬럼에 'Economist'라는 단어가 포함된 직원만 조회된다.
- 예시: SELECT * FROM Orders WHERE OrderID LIKE '1025_';를 실행하면 OrderID가 '1025'로 시작하고 그 뒤에 한 자리 숫자가 오는 주문만 조회된다.
- 숫자 데이터에도 문자열 패턴 매칭을 적용할 수 있다.
23. MySQL 함수: 숫자 함수
23.1. 반올림, 올림, 내림
- ROUND(값): 반올림 (0.5 이상은 올림, 미만은 내림).
- CEIL(값): 올림 (무조건 올림).
- FLOOR(값): 내림 (무조건 내림).
- 예시: SELECT ROUND(0.5), CEIL(0.4), FLOOR(0.6);을 실행하면 각각 1, 1, 0이 출력된다.
- 테이블 적용: Price 컬럼에 적용하여 가격을 반올림, 올림, 내림할 수 있다.
23.2. 절대값
- ABS(값): 절대값을 반환한다 (부호와 관계없이 양수로 변환).
- 예시: SELECT ABS(1), ABS(-1), ABS(-7);을 실행하면 각각 1, 1, 7이 출력된다.
- 테이블 적용: Quantity 컬럼에 적용하여 특정 값과의 차이의 절대값을 구할 수 있다.
- 예시: SELECT * FROM OrderDetails WHERE ABS(Quantity - 10) < 5;를 실행하면 Quantity가 10에서 5만큼 차이나는 범위(5~14)에 있는 주문 상세 정보가 조회된다.
23.3. 최대/최소값 (GREATEST, LEAST)

- GREATEST(값1, 값2, ...): 괄호 안에 있는 값들 중 가장 큰 값을 반환한다.
- LEAST(값1, 값2, ...): 괄호 안에 있는 값들 중 가장 작은 값을 반환한다.
- 예시: SELECT GREATEST(10, 20, 0), LEAST(10, 20, 0);을 실행하면 각각 20, 0이 출력된다.
- 테이블 적용: OrderID, ProductID, Quantity 컬럼들 중에서 가장 큰 값과 작은 값을 선택할 수 있다.
23.4. 집계 함수 (MAX, MIN, COUNT, SUM, AVG)
- MAX(컬럼명): 특정 컬럼의 행들 중 최대값을 반환한다.
- MIN(컬럼명): 특정 컬럼의 행들 중 최소값을 반환한다.
- COUNT(컬럼명): 특정 컬럼의 행 개수를 센다.
- SUM(컬럼명): 특정 컬럼의 값들을 모두 더한 총합을 반환한다.
- AVG(컬럼명): 특정 컬럼의 값들의 평균을 반환한다.
- WHERE 절과 함께 사용: WHERE 절로 조건을 걸어 특정 범위 내의 데이터에 대해서만 집계 함수를 적용할 수 있다.
- 예시: SELECT MAX(Quantity), MIN(Quantity), COUNT(Quantity), SUM(Quantity), AVG(Quantity) FROM OrderDetails WHERE OrderDetailID BETWEEN 20 AND 30;를 실행하면 OrderDetailID가 20에서 30 사이인 주문 상세 정보의 Quantity에 대한 최대, 최소, 개수, 합계, 평균이 출력된다.
- 전체 테이블 적용: WHERE 절 없이 사용하면 테이블 전체 데이터에 대해 집계 함수를 적용한다.
- 그룹 함수: 이 함수들은 챕터 1의 5강에서 GROUP BY와 함께 더 자세히 다룬다.
23.5. 제곱 및 제곱근
- POWER(밑, 지수): 밑을 지수만큼 제곱한 값을 반환한다.
- SQRT(값): 값의 제곱근을 반환한다.
- 예시: SELECT POWER(2, 3), POWER(5, 2), SQRT(16);을 실행하면 각각 8, 25, 4가 출력된다.
- 테이블 적용: Price 컬럼에 제곱근을 적용하여 필터링할 수 있다.
- 예시: SELECT * FROM Products WHERE SQRT(Price) < 4;를 실행하면 Price의 제곱근이 4보다 작은 제품만 조회된다.
23.6. 숫자 자르기 (TRUNCATE)
- TRUNCATE(값, 자릿수): 숫자를 지정된 자릿수만큼 자른다 (반올림 없음).
- 양수 자릿수: 소수점 뒤로 해당 자릿수만큼 남기고 자른다.
- 예시: TRUNCATE(1234.5678, 2) -> 1234.56
- 음수 자릿수: 소수점 앞으로 해당 자릿수만큼 0으로 채운다.
- 예시: TRUNCATE(1234.5678, -2) -> 1200
- 양수 자릿수: 소수점 뒤로 해당 자릿수만큼 남기고 자른다.
- 테이블 적용: Price 컬럼을 소수점 이하를 자르거나 특정 자릿수에서 자를 수 있다.
- 예시: SELECT * FROM Products WHERE TRUNCATE(Price, 0) = 12;를 실행하면 Price를 소수점 이하를 자른 값이 12인 제품만 조회된다.
- 이처럼 TRUNCATE를 활용하여 다양한 조건문을 프로그래밍할 수 있다.
24. MySQL 함수: 문자열 함수
24.1. 대소문자 변환 (UPPER, LOWER)
- UPPER(문자열): 주어진 텍스트를 모두 대문자로 변환한다.
- LOWER(문자열): 주어진 텍스트를 모두 소문자로 변환한다.
- 예시: SELECT UPPER('hello'), LOWER('HELLO');를 실행하면 각각 'HELLO', 'hello'가 출력된다.
- 테이블 적용: CustomerName, ContactName 컬럼을 대소문자로 변환하여 출력할 수 있다.
24.2. 문자열 연결 (CONCAT, CONCAT_WS)
- CONCAT(문자열1, 문자열2, ...): 여러 문자열을 이어 붙여 하나의 문자열로 만든다.
- 다른 프로그래밍 언어에서는 + 연산자로 문자열을 더할 수 있지만, MySQL에서는 CONCAT 함수를 사용한다.
- 숫자도 문자열로 변환되어 연결된다.
- 예시: SELECT CONCAT('Hello', ' ', 'This is ', 2021);을 실행하면 'Hello This is 2021'이 출력된다.
- CONCAT_WS(구분자, 문자열1, 문자열2, ...): 맨 앞에 주어진 구분자를 나머지 문자열들 사이에 넣어 하나의 문자열로 만든다.
- 예시: SELECT CONCAT_WS('-', 2021, 12, 25);를 실행하면 '2021-12-25'가 출력된다.
- 테이블 적용:
- OrderID 앞에 특정 문자열을 붙여 출력할 수 있다.
- FirstName과 LastName 컬럼을 합쳐 FullName 컬럼으로 출력할 수 있다.
24.3. 문자열 자르기 (SUBSTRING, LEFT, RIGHT)
- SUBSTRING(문자열, 시작위치, 길이): 문자열의 특정 부분만 잘라낸다.
- 시작위치 (양수): 왼쪽에서부터 시작하여 해당 위치부터 자른다. (MySQL은 1부터 시작)
- 예시: SUBSTRING('abcdefg', 3) -> 'cdefg'
- 시작위치 (음수): 오른쪽에서부터 시작하여 해당 위치부터 자른다.
- 예시: SUBSTRING('abcdefg', -4) -> 'defg'
- 길이: 시작위치부터 지정된 길이만큼 자른다.
- 예시: SUBSTRING('abcdefg', 3, 2) -> 'cd'
- 시작위치 (양수): 왼쪽에서부터 시작하여 해당 위치부터 자른다. (MySQL은 1부터 시작)
- LEFT(문자열, 길이): 문자열의 왼쪽에서부터 지정된 길이만큼 자른다.
- 예시: LEFT('abcdefg', 3) -> 'abc'
- RIGHT(문자열, 길이): 문자열의 오른쪽에서부터 지정된 길이만큼 자른다.
- 예시: RIGHT('abcdefg', 3) -> 'efg'
- 테이블 적용: OrderDate 컬럼에서 연, 월, 일을 각각 분리하여 출력할 수 있다.
- 예시: SELECT LEFT(OrderDate, 4) AS Year, SUBSTRING(OrderDate, 6, 2) AS Month, RIGHT(OrderDate, 2) AS Day FROM Orders;
24.4. 문자열 길이 (LENGTH, CHAR_LENGTH)
- LENGTH(문자열): 문자열의 바이트 길이를 반환한다.
- CHAR_LENGTH(문자열): 문자열의 실제 글자 개수를 반환한다.
- 차이점:
- 영어의 경우, 보통 글자 수와 바이트 수가 동일하게 나온다.
- 한글의 경우, 한 글자가 여러 바이트를 차지할 수 있으므로 LENGTH와 CHAR_LENGTH의 결과가 다르게 나온다.
- 예시: '안녕하세요' (5글자)의 CHAR_LENGTH는 5, LENGTH는 15 (한글 한 글자당 3바이트)가 나올 수 있다.
- 일반적으로 한글을 포함한 글자 수를 셀 때는 CHAR_LENGTH를 사용해야 원하는 결과를 얻을 수 있다.
24.5. 공백 제거 (TRIM, LTRIM, RTRIM)
- TRIM(문자열): 문자열의 양쪽 끝에 있는 공백을 제거한다.
- LTRIM(문자열): 문자열의 왼쪽 끝에 있는 공백을 제거한다.
- RTRIM(문자열): 문자열의 오른쪽 끝에 있는 공백을 제거한다.
- 예시: SELECT CONCAT('|', TRIM(' Hello '), '|');을 실행하면 '|Hello|'가 출력된다.
- 테이블 적용: CategoryName 컬럼에 공백이 포함되어 있을 때, TRIM을 사용하여 정확한 검색을 할 수 있다.
- 예시: SELECT * FROM Categories WHERE TRIM(CategoryName) = 'Beverages';를 실행하면 양쪽 공백이 제거된 'Beverages'와 일치하는 카테고리만 조회된다.
24.6. 문자열 채우기 (LPAD, RPAD)
- LPAD(문자열, 전체길이, 채울문자): 문자열의 왼쪽에 지정된 문자를 채워 전체 길이를 맞춘다.
- RPAD(문자열, 전체길이, 채울문자): 문자열의 오른쪽에 지정된 문자를 채워 전체 길이를 맞춘다.
- 예시: SELECT LPAD('abc', 5, '0'), RPAD('abc', 5, '<em>');를 실행하면 각각 '00abc', 'abc*'가 출력된다.
- 테이블 적용: SupplierID나 Price 컬럼의 숫자를 특정 길이로 맞추기 위해 왼쪽에 0을 채우거나 오른쪽에 0을 채울 수 있다.
- 예시: SELECT LPAD(SupplierID, 5, '0') FROM Products;를 실행하면 SupplierID가 5자리로 왼쪽에 0이 채워져 출력된다.
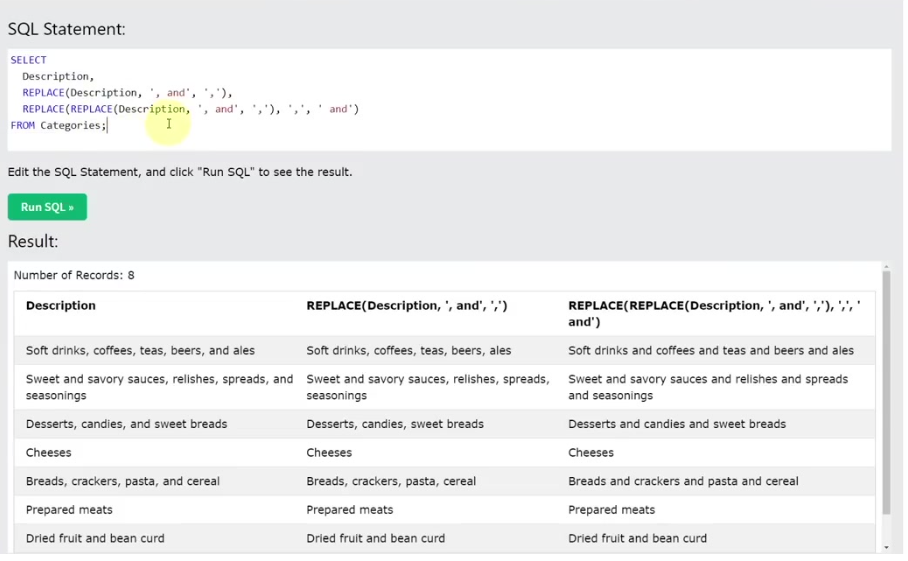
24.7. 문자열 교체 (REPLACE)
- REPLACE(문자열, 찾을문자열, 바꿀문자열): 주어진 문자열에서 특정 문자열을 찾아 다른 문자열로 모두 교체한다.
- 예시: SELECT REPLACE('맥도날드에서 맥도날드 햄버거를 먹었다', '맥도날드', '버거킹');을 실행하면 '버거킹에서 버거킹 햄버거를 먹었다'가 출력된다.
- 테이블 적용: Description 컬럼에서 쉼표(,)를 AND로 교체하거나, 여러 번의 REPLACE 함수를 중첩하여 복잡한 문자열 변환을 할 수 있다.
- 예시: SELECT REPLACE(Description, ',', ' AND ') FROM Categories;를 실행하면 Description의 쉼표가 ' AND '로 바뀐다.
- REPLACE 함수를 중첩하여 AND를 쉼표로 바꾼 후 다시 쉼표를 AND로 바꾸는 등 복잡한 변환을 통해 원하는 형식으로 만들 수 있다.
24.8. 문자열 내 위치 찾기 (INSTR)
- INSTR(문자열, 찾을문자열): 첫 번째 문자열에서 두 번째 문자열이 나타나는 시작 위치를 반환한다. 없으면 0을 반환한다.
- 예시: SELECT INSTR('abcdefg', 'c');를 실행하면 3이 출력된다.
- 활용: 문자열 내 특정 문자의 위치를 찾아 조건문 등에 활용할 수 있다.
- 예시: SELECT * FROM Customers WHERE INSTR(CustomerName, ' ') BETWEEN 1 AND 6;를 실행하면 CustomerName에 공백이 있고 그 위치가 1에서 6 사이인 고객만 조회된다. (즉, 이름이 짧은 고객)
24.9. 자료형 변환 (CAST)
- CAST(값 AS 자료형): 주어진 값을 원하는 자료형으로 변환한다.
- 필요성: MySQL을 비롯한 프로그래밍 언어는 데이터마다 숫자, 문자열, 참/거짓 등의 자료형이 있으며, CAST는 이를 명확히 변환하는 역할을 한다.
- 예시:
- SELECT '0' = '1';을 실행하면 0(FALSE)이 출력된다. ('0'과 '1'은 문자열이므로 다르다)
- SELECT CAST('0' AS DECIMAL) = CAST('1' AS DECIMAL);을 실행하면 0(FALSE)이 출력된다. (둘 다 숫자로 변환되었지만 여전히 다르다)
- SELECT CAST('1' AS DECIMAL) = 1;을 실행하면 1(TRUE)이 출력된다. (문자열 '1'이 숫자 1로 변환되어 비교)
- 활용: 문자열 형태의 숫자를 실제 숫자로 변환하여 연산하거나 비교할 때 사용한다.
25. MySQL 함수: 날짜 및 시간 함수
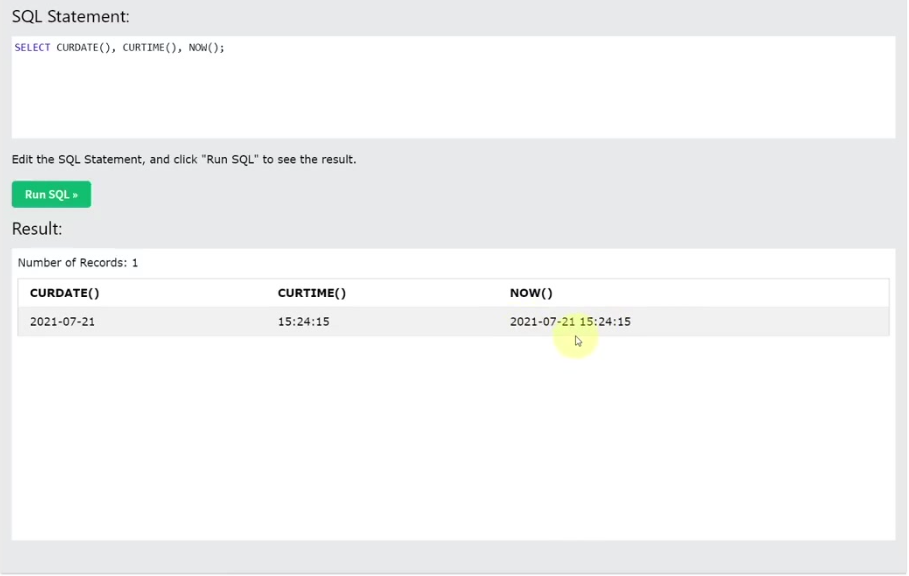
25.1. 현재 날짜/시간 가져오기
- CURDATE(): 현재 날짜를 반환한다.
- CURTIME(): 현재 시간을 반환한다.
- NOW(): 현재 날짜와 시간을 모두 반환한다.
- CURDATE()와 CURTIME()을 합친 것과 같다.
- 괄호: 인자가 없어도 함수이므로 빈 괄호 ()를 붙여야 한다.
- 예시: SELECT CURDATE(), CURTIME(), NOW();를 실행하면 현재 날짜, 현재 시간, 현재 날짜와 시간이 모두 출력된다.
25.2. 문자열을 날짜/시간으로 변환 (DATE, TIME, DATETIME)
- DATE(문자열): 문자열을 날짜 정보로 변환한다.
- TIME(문자열): 문자열을 시간 정보로 변환한다.
- DATETIME(문자열): 문자열을 날짜 및 시간 정보로 변환한다.
- 필요성: MySQL은 문자열을 그대로 텍스트로 인식하므로, 날짜/시간 형식의 문자열을 실제 날짜/시간 정보로 변환해야 정확한 비교나 연산이 가능하다.
- 예시: '2021-06-01'과 '2021-06-01'은 문자열로 같지만, DATE('2021-06-01')과 DATE('2021-06-01')은 실제 날짜 정보로 변환되어 비교된다.
- 특징:
- DATE() 함수는 문자열에서 날짜 부분만 추출하여 변환하고, 시간 부분은 무시한다.
- TIME() 함수는 문자열에서 시간 부분만 추출하여 변환하고, 날짜 부분은 무시한다.
- 따라서 DATE()로 변환된 값과 TIME()으로 변환된 값은 서로 다르다.
- WHERE 절에서의 활용:
- 예시: SELECT * FROM Orders WHERE OrderDate BETWEEN DATE('1997-01-01') AND DATE('1997-01-31');를 실행하면 OrderDate가 1997년 1월 1일부터 1월 31일 사이인 주문만 조회된다.
25.3. 날짜/시간 구성 요소 추출 (YEAR, MONTHNAME, MONTH, WEEKDAY, DAYNAME, DAYOFMONTH)
- YEAR(날짜): 날짜에서 연도를 추출한다.
- MONTHNAME(날짜): 날짜에서 월 이름을 영문으로 추출한다 (예: 'January').
- MONTH(날짜): 날짜에서 월을 숫자로 추출한다 (예: 1, 2, 3).
- WEEKDAY(날짜): 날짜에서 요일을 숫자로 추출한다 (월요일=0, 화요일=1, ...).
- DAYNAME(날짜): 날짜에서 요일 이름을 영문으로 추출한다 (예: 'Monday').
- DAYOFMONTH(날짜): 날짜에서 일을 숫자로 추출한다.
- 테이블 적용: OrderDate 컬럼에서 연도, 월 이름, 월 숫자, 요일 숫자, 일자 등을 추출하여 출력할 수 있다.
- 함수 중첩 활용: 여러 날짜/시간 함수와 문자열 함수를 중첩하여 원하는 형식의 날짜 문자열을 만들 수 있다.
- 예시: CONCAT_WS('/', YEAR(OrderDate), MONTH(OrderDate), DAYOFMONTH(OrderDate))와 같이 연/월/일을 슬래시로 연결하거나, LEFT(DAYNAME(OrderDate), 3)과 같이 요일 이름을 줄여서 표시할 수 있다.
- WHERE 절에서의 활용: 특정 요일이나 월에 해당하는 데이터만 필터링할 수 있다.
- 예시: SELECT * FROM Orders WHERE WEEKDAY(OrderDate) = 0;를 실행하면 월요일에 주문된 내역만 조회된다.
25.4. 시간 구성 요소 추출 (HOUR, MINUTE, SECOND)
- HOUR(시간): 시간에서 시를 추출한다.
- MINUTE(시간): 시간에서 분을 추출한다.
- SECOND(시간): 시간에서 초를 추출한다.
- 예시: SELECT HOUR(NOW()), MINUTE(NOW()), SECOND(NOW());를 실행하면 현재 시간의 시, 분, 초가 각각 출력된다.
25.5. 날짜/시간 더하기/빼기 (DATE_ADD, DATE_SUB)
- DATE_ADD(날짜/시간, INTERVAL 값 단위): 날짜/시간에 특정 기간을 더한다.
- DATE_SUB(날짜/시간, INTERVAL 값 단위): 날짜/시간에서 특정 기간을 뺀다.
- 단위: YEAR, MONTH, DAY, HOUR, MINUTE, SECOND 등 다양한 단위를 사용할 수 있다.
- 예시: SELECT DATE_ADD('2021-06-20', INTERVAL 1 YEAR);를 실행하면 2022-06-20이 출력된다.
- 테이블 적용: OrderDate 컬럼에 연, 월, 일 등을 더하거나 빼서 새로운 날짜를 구할 수 있다.
- 예시: SELECT OrderDate, DATE_ADD(OrderDate, INTERVAL 1 MONTH) AS NextMonth FROM Orders;
25.6. 날짜/시간 차이 계산 (DATEDIFF, TIMEDIFF)
- DATEDIFF(날짜1, 날짜2): 두 날짜 간의 일수 차이를 반환한다.
- TIMEDIFF(시간1, 시간2): 두 시간 간의 시간 차이를 반환한다.
- 예시: SELECT DATEDIFF(NOW(), OrderDate) FROM Orders;를 실행하면 현재 날짜와 주문 날짜 간의 일수 차이가 출력된다.
- 순서를 바꾸면 양수/음수가 바뀐다.
- ABS() 함수를 사용하여 절대값 차이를 구할 수 있다.
- WHERE 절에서의 활용:
- 예시: SELECT * FROM Orders WHERE ABS(DATEDIFF(OrderDate, '1996-10-10')) <= 4;를 실행하면 OrderDate가 1996년 10월 10일로부터 4일 이내인 주문만 조회된다.
25.7. 월의 마지막 날짜 (LAST_DAY)
- LAST_DAY(날짜): 주어진 날짜가 속한 월의 마지막 날짜를 반환한다.
- 예시: SELECT LAST_DAY('1996-09-10');을 실행하면 '1996-09-30'이 출력된다.
- 활용: 해당 월의 마지막 날짜를 기준으로 요일을 구하거나, 남은 일수를 계산하는 등 다양한 응용이 가능하다.
25.8. 날짜/시간 형식 지정 (DATE_FORMAT)

- DATE_FORMAT(날짜/시간, 형식문자열): 날짜/시간을 지정된 형식의 문자열로 표현한다.
- 형식 문자열: %Y (4자리 연도), %y (2자리 연도), %M (영문 월 이름), %m (숫자 월), %d (일), %H (24시), %h (12시), %i (분), %s (초), %p (AM/PM) 등 다양한 형식 지정자가 있다.
- 예시: SELECT DATE_FORMAT(NOW(), '%Y년 %m월 %d일 %H시 %i분 %s초');를 실행하면 현재 날짜와 시간이 '2023년 10월 27일 15시 30분 00초'와 같은 형식으로 출력된다.
- 문자열 함수와 중첩: REPLACE 함수 등을 중첩하여 AM/PM을 '오전/오후'로 바꾸는 등 복잡한 형식 변환을 할 수 있다.
25.9. 문자열을 날짜/시간으로 파싱 (STR_TO_DATE)

- STR_TO_DATE(문자열, 형식문자열): 주어진 문자열을 지정된 형식대로 해석하여 날짜/시간 정보로 생성한다.
- 활용: 특정 형식의 문자열을 날짜/시간으로 변환하여 다른 날짜/시간 값과 비교하거나 연산할 때 사용한다.
- 예시: SELECT * FROM Orders WHERE OrderDate = STR_TO_DATE('1996-07-04', '%Y-%m-%d');를 실행하면 '1996-07-04' 문자열을 날짜로 변환하여 OrderDate와 비교한다.
26. MySQL 함수: 기타 함수
26.1. 조건문 (IF, CASE)
- IF(조건, 참일때_값, 거짓일때_값): 첫 번째 인자인 조건이 참이면 두 번째 값을, 거짓이면 세 번째 값을 반환한다.
- 예시: SELECT IF(1 > 2, '참', '거짓');을 실행하면 '거짓'이 출력된다.
- CASE WHEN 조건1 THEN 값1 WHEN 조건2 THEN 값2 ELSE 값3 END: 여러 조건에 따라 다른 값을 반환할 때 사용한다.
- CASE로 시작하여 WHEN ... THEN 구문을 사용하고, 모든 조건에 해당하지 않을 경우 ELSE 값을 반환하며, END로 마무리한다.
- 예시: SELECT CASE WHEN -1 > 0 THEN '양수' WHEN -1 = 0 THEN '0' ELSE '음수' END;를 실행하면 '음수'가 출력된다.
- 테이블 적용: Products 테이블의 Price 컬럼을 기준으로 IF와 CASE 문을 활용하여 'Expensive', 'Cheap', 'Low', 'Normal', 'High' 등으로 분류하여 출력할 수 있다.
26.2. NULL 값 처리 (IFNULL)
- IFNULL(값1, 값2): 첫 번째 값이 NULL이 아니면 첫 번째 값을 반환하고, NULL이면 두 번째 값을 반환한다.
- 활용: 컬럼에 NULL 값이 있을 때, 대신 다른 값(예: '없음', 0)을 출력하도록 할 수 있다.
- 예시: SELECT IFNULL(NULL, '없음');을 실행하면 '없음'이 출력된다.
- 실습: 현재는 NULL 값이 있는 테이블이 없으므로, 챕터 2에서 JOIN을 다룰 때 IFNULL을 사용해 볼 예정이다.
27. GROUP BY 절을 이용한 그룹화
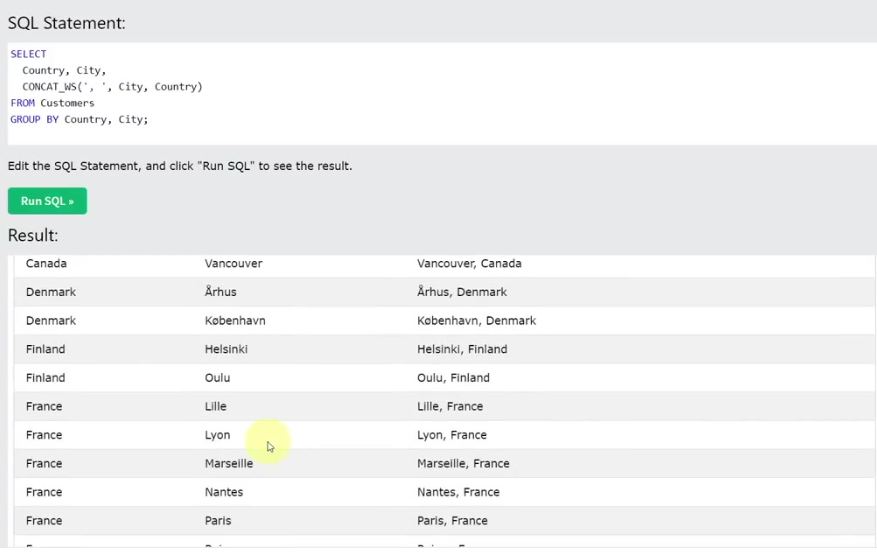
27.1. GROUP BY 기본 사용법
- SELECT 컬럼명 FROM 테이블명 GROUP BY 컬럼명;: GROUP BY 절을 사용하여 특정 컬럼의 값이 같은 행들을 그룹으로 묶는다.
- 목적: 중복되는 값을 제거하고, 각 그룹별로 고유한 값만 가져올 때 사용한다.
- 예시: SELECT Country FROM Customers GROUP BY Country;를 실행하면 Customers 테이블의 모든 국가가 중복 없이 하나씩 출력된다.
- 복수 컬럼 그룹화: 여러 컬럼을 기준으로 그룹화할 수 있으며, 이 컬럼들의 조합이 같은 행들끼리 묶인다.
- 예시: SELECT Country, City, CONCAT_WS(', ', Country, City) FROM Customers GROUP BY Country, City;를 실행하면 Country와 City의 조합이 겹치지 않는 데이터가 출력된다.
27.2. GROUP BY와 집계 함수 활용
- SELECT 컬럼명, 집계함수(컬럼명) FROM 테이블명 GROUP BY 컬럼명;: GROUP BY와 COUNT, SUM, AVG, MAX, MIN 등의 집계 함수를 함께 사용하여 각 그룹별로 통계 정보를 계산할 수 있다.
- 예시:
- SELECT OrderDate, COUNT(*) FROM Orders GROUP BY OrderDate;를 실행하면 각 날짜별로 몇 개의 주문이 있었는지(행의 개수)를 알 수 있다.
- 복수 집계 함수 및 정렬: 여러 집계 함수를 사용하고 ORDER BY로 정렬할 수 있다.
- 예시: SELECT ProductID, SUM(Quantity) AS TotalQuantity FROM OrderDetails GROUP BY ProductID ORDER BY TotalQuantity DESC;를 실행하면 각 제품 ID별 총 수량을 내림차순으로 정렬하여 출력한다.
- 복잡한 통계: 여러 집계 함수를 조합하여 각 카테고리별 최고 가격, 최소 가격, 중간값(미디안), 평균 가격 등을 구할 수 있다.
- 예시: SELECT CategoryID, MAX(Price) AS MaxPrice, MIN(Price) AS MinPrice, (MAX(Price) + MIN(Price)) / 2 AS MedianPrice, AVG(Price) AS AvgPrice FROM Products GROUP BY CategoryID;
- COUNT(컬럼명) vs COUNT(<em>): COUNT(컬럼명)은 해당 컬럼에 NULL이 아닌 값의 개수를 세고, COUNT(</em>)는 모든 행의 개수를 센다.
27.3. WITH ROLLUP
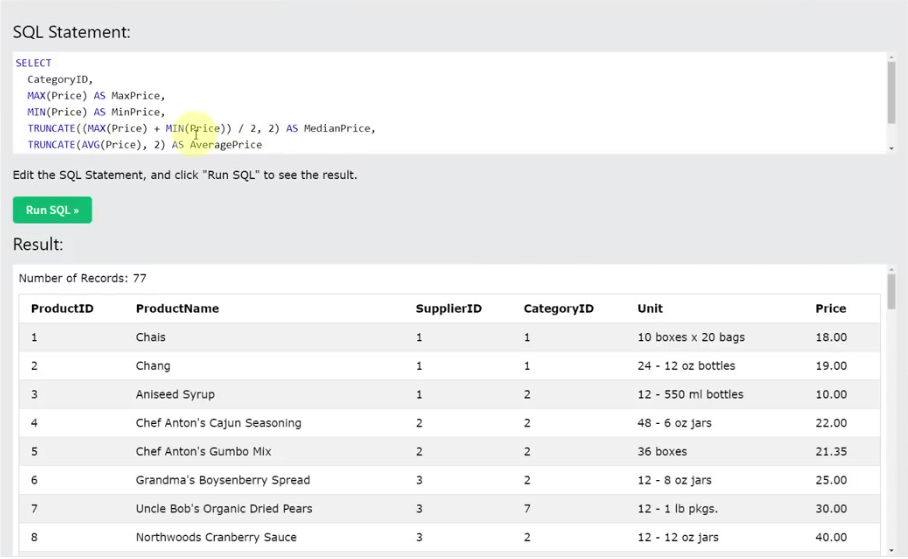
- GROUP BY 컬럼명 WITH ROLLUP;: GROUP BY 결과에 전체 합계(총계) 행을 추가한다.
- 특징:
- 총계 행은 그룹화된 컬럼 값이 NULL로 표시되고, 집계 함수 결과에는 전체 합계가 들어간다.
- ORDER BY 절과 함께 사용할 수 없다.
- 예시: SELECT Country, COUNT(*) FROM Customers GROUP BY Country WITH ROLLUP;을 실행하면 각 국가별 고객 수와 함께 전체 고객 수가 추가된 행이 출력된다.
28. HAVING 절을 이용한 그룹 필터링
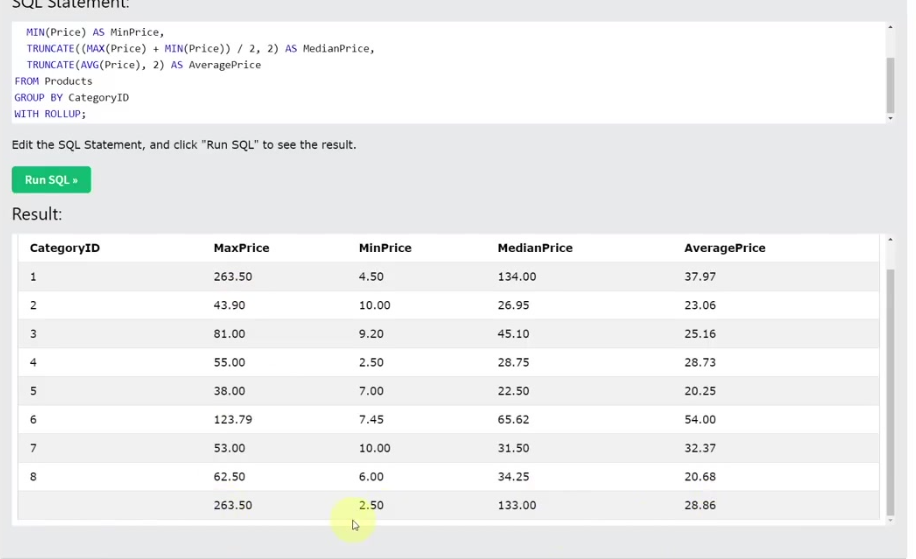
- SELECT ... GROUP BY ... HAVING 조건;: HAVING 절은 GROUP BY로 그룹화된 결과에 조건을 적용하여 필터링한다.
- WHERE vs HAVING:
- WHERE 절은 그룹화하기 전의 개별 행 데이터에 조건을 적용한다.
- HAVING 절은 그룹화된 후의 집계 결과에 조건을 적용한다.
- 따라서 HAVING 절에는 집계 함수를 사용한 조건을 넣을 수 있다.
- 예시:
- SELECT Country, COUNT(<em>) FROM Suppliers GROUP BY Country HAVING COUNT(</em>) >= 3;를 실행하면 각 국가별 공급자 수가 3개 이상인 국가만 조회된다.
- WHERE와 HAVING 동시 사용: WHERE 절로 먼저 개별 행을 필터링한 후, GROUP BY로 그룹화하고, HAVING 절로 그룹화된 결과에 다시 조건을 적용할 수 있다.
- 예시: SELECT OrderDate, COUNT(<em>) FROM Orders WHERE OrderDate > '1996-07-04' GROUP BY OrderDate HAVING COUNT(</em>) > 1;를 실행하면 1996년 7월 4일 이후의 주문 중, 각 날짜별 주문 건수가 1개를 초과하는 날짜만 조회된다.
29. DISTINCT 키워드를 이용한 중복 제거
- SELECT DISTINCT 컬럼명 FROM 테이블명;: DISTINCT 키워드를 SELECT 절에 사용하여 특정 컬럼의 중복된 값을 제거하고 고유한 값만 가져온다.
- GROUP BY와의 차이점:
- DISTINCT는 단순히 중복을 제거하여 고유한 값만 가져오며, 기본적으로 정렬되지 않는다.
- GROUP BY는 값을 기준으로 그룹을 만들고, 각 그룹에 대해 집계 함수를 적용할 수 있다.
- DISTINCT는 집계 함수와 함께 사용할 수 없다.
- ORDER BY와 함께 사용: DISTINCT로 중복을 제거한 후 ORDER BY를 사용하여 정렬할 수 있다.
- 예시: SELECT DISTINCT Country FROM Customers ORDER BY Country;를 실행하면 중복 없는 국가 목록이 알파벳 순으로 정렬되어 출력된다.
- 복수 컬럼 중복 제거: 여러 컬럼을 DISTINCT와 함께 사용하면 해당 컬럼들의 조합이 중복되지 않는 데이터만 가져온다.
- 예시: SELECT DISTINCT Country, City FROM Customers;를 실행하면 Country와 City의 조합이 중복되지 않는 데이터가 출력된다.
- GROUP BY와 DISTINCT의 조합: GROUP BY 내에서 COUNT(DISTINCT 컬럼명)과 같이 사용하여 그룹 내에서 중복되지 않는 값의 개수를 셀 수 있다.
- 예시: SELECT Country, COUNT(DISTINCT City) FROM Customers GROUP BY Country;를 실행하면 각 국가별로 중복되지 않는 도시의 개수를 셀 수 있다.
30. 서브쿼리 (Subquery)
30.1. 비상관 서브쿼리 (Non-correlated Subquery)
- 정의: 메인 쿼리와 독립적으로 실행되며, 서브쿼리의 결과가 메인 쿼리에 영향을 미치는 방식이다.
- SELECT 절 내 서브쿼리: SELECT 절 안에 서브쿼리를 넣어 다른 테이블의 정보를 함께 가져올 수 있다.
- 예시: SELECT CategoryID, CategoryName, Description, (SELECT ProductName FROM Products WHERE CategoryID = Categories.CategoryID LIMIT 1) AS SampleProduct FROM Categories;를 실행하면 각 카테고리별 정보와 함께 해당 카테고리의 샘플 제품명이 출력된다.
- WHERE 절 내 서브쿼리 (단일 값 반환): WHERE 절에 서브쿼리를 넣어 조건을 지정할 수 있으며, 이때 서브쿼리는 단일 값을 반환해야 한다.
- 예시: SELECT * FROM Products WHERE Price < (SELECT AVG(Price) FROM Products);를 실행하면 제품 가격이 전체 제품의 평균 가격보다 낮은 제품만 조회된다.
- 예시: SELECT * FROM Categories WHERE CategoryID = (SELECT CategoryID FROM Products WHERE ProductName = 'Chai');를 실행하면 'Chai' 제품이 속한 카테고리만 조회된다.
- WHERE 절 내 서브쿼리 (여러 값 반환 - IN 사용): 서브쿼리가 여러 값을 반환할 경우, IN 연산자와 함께 사용한다.
- 예시: SELECT * FROM Categories WHERE CategoryID IN (SELECT CategoryID FROM Products WHERE Price > 50);를 실행하면 가격이 50을 초과하는 제품이 속한 카테고리만 조회된다.
30.2. ALL 및 ANY 연산자
- ALL 연산자: 서브쿼리에서 반환되는 모든 값에 대해 조건이 참일 때 메인 쿼리의 조건이 참이 된다.
- 예시: SELECT * FROM Products WHERE Price > ALL (SELECT Price FROM Products WHERE CategoryID = 2);를 실행하면 CategoryID가 2인 모든 제품의 가격보다 높은 제품만 조회된다.
- 이는 CategoryID가 2인 제품 중 가장 높은 가격보다 높은 제품을 찾는 것과 같다.
- 예시: SELECT * FROM Products WHERE Price > ALL (SELECT Price FROM Products WHERE CategoryID = 2);를 실행하면 CategoryID가 2인 모든 제품의 가격보다 높은 제품만 조회된다.
- ANY 연산자: 서브쿼리에서 반환되는 값들 중 어느 하나라도 조건이 참일 때 메인 쿼리의 조건이 참이 된다.
- 예시: SELECT * FROM Products WHERE Price = ANY (SELECT Price FROM Products WHERE CategoryID = 2);를 실행하면 CategoryID가 2인 제품 중 어느 하나의 가격과라도 같은 제품이 조회된다.
- 이는 IN 연산자와 동일한 결과를 반환한다.
- 예시: SELECT * FROM Products WHERE Price = ANY (SELECT Price FROM Products WHERE CategoryID = 2);를 실행하면 CategoryID가 2인 제품 중 어느 하나의 가격과라도 같은 제품이 조회된다.
30.3. 상관 서브쿼리 (Correlated Subquery)
- 정의: 서브쿼리가 메인 쿼리의 각 행에 대해 한 번씩 실행되며, 메인 쿼리의 값에 의존하는 방식이다.
- 메인 쿼리의 테이블에 별칭(Alias)을 부여하고, 서브쿼리에서 이 별칭을 참조하여 메인 쿼리의 현재 행과 관련된 데이터를 처리한다.
- SELECT 절 내 상관 서브쿼리:
- 예시: SELECT p.ProductName, (SELECT c.CategoryName FROM Categories c WHERE c.CategoryID = p.CategoryID) AS CategoryName FROM Products p;를 실행하면 각 제품명과 함께 해당 제품의 카테고리 이름이 출력된다.
- 이는 JOIN 문법으로 더 쉽게 구현할 수 있지만, 서브쿼리의 동작 방식을 이해하는 데 중요하다.
- WHERE 절 내 상관 서브쿼리:
- 예시: SELECT s.SupplierName, s.Country, s.City, (SELECT COUNT(*) FROM Customers c WHERE c.Country = s.Country AND c.City = s.City) AS CustomersInCity FROM Suppliers s;를 실행하면 각 공급자 정보와 함께 해당 공급자가 위치한 국가 및 도시에 거주하는 고객 수가 출력된다.
- 예시: SELECT c.CategoryName, (SELECT MAX(p.Price) FROM Products p WHERE p.CategoryID = c.CategoryID) AS MaxPrice, (SELECT AVG(p.Price) FROM Products p WHERE p.CategoryID = c.CategoryID) AS AvgPrice FROM Categories c;를 실행하면 각 카테고리별 최고 가격과 평균 가격이 출력된다.
- 예시: SELECT p1.ProductName, p1.Price FROM Products p1 WHERE p1.Price < (SELECT AVG(p2.Price) FROM Products p2 WHERE p2.CategoryID = p1.CategoryID);를 실행하면 각 제품 중 해당 카테고리의 평균 가격보다 낮은 제품만 조회된다.
30.4. EXISTS 및 NOT EXISTS 연산자
- EXISTS (서브쿼리): 서브쿼리의 결과가 하나라도 존재하면 참(TRUE)을 반환한다.
- NOT EXISTS (서브쿼리): 서브쿼리의 결과가 하나도 존재하지 않으면 참(TRUE)을 반환한다.
- 활용: 특정 조건을 만족하는 데이터가 존재하는지 여부를 기준으로 메인 쿼리를 필터링할 때 사용한다.
- 예시: SELECT c.CategoryName FROM Categories c WHERE EXISTS (SELECT p.ProductID FROM Products p WHERE p.CategoryID = c.CategoryID AND p.Price > 80);를 실행하면 가격이 80을 초과하는 제품이 하나라도 있는 카테고리만 조회된다.
31. JOIN (테이블 결합)
31.1. INNER JOIN (기본 JOIN)
- 정의: 두 테이블에서 ON 절의 조건이 일치하는 행들만 결합하여 가져온다. MySQL에서 JOIN이라고만 쓰면 기본적으로 INNER JOIN이다.
- 필요성: 데이터 중복을 피하기 위해 분리된 테이블들을 필요에 따라 다시 합쳐서 조회할 때 사용한다.
- 문법: SELECT 컬럼 FROM 테이블1 JOIN 테이블2 ON 테이블1.컬럼 = 테이블2.컬럼;
- ON 절에 두 테이블을 연결할 기준 컬럼을 명시한다.
- 예시: SELECT * FROM Categories c JOIN Products p ON c.CategoryID = p.CategoryID;를 실행하면 Categories 테이블과 Products 테이블을 CategoryID를 기준으로 결합하여 출력한다.
- 결과: Products 테이블의 내용과 Categories 테이블의 내용이 CategoryID가 같은 행들끼리 묶여서 하나의 테이블처럼 조회된다.
- 컬럼명 명시:
- 두 테이블에 동일한 이름의 컬럼이 있을 경우, 테이블명.컬럼명 또는 테이블별칭.컬럼명으로 명시하여 어떤 테이블의 컬럼인지 구분해야 한다.
- SELECT 절에서 원하는 컬럼만 선택하여 출력할 수 있다.
- WHERE 절과 함께 사용: JOIN 결과에 WHERE 절로 추가 조건을 적용할 수 있다.
- 예시: SELECT p.ProductName, p.Price, s.SupplierName FROM Products p JOIN Suppliers s ON p.SupplierID = s.SupplierID WHERE p.Price > 50;를 실행하면 가격이 50보다 높은 제품과 해당 공급자 정보가 조회된다.
- 여러 테이블 JOIN: 2개 이상의 테이블을 연속적으로 JOIN할 수 있다.
- 예시: Categories, Products, OrderDetails, Orders 4개 테이블을 각각의 ID를 기준으로 JOIN할 수 있다.
- SELECT *로 조회하면 매우 많은 컬럼이 출력될 수 있으므로, 필요한 컬럼만 선택하는 것이 좋다.
- JOIN 결과 그룹화: JOIN된 테이블의 결과를 GROUP BY와 집계 함수를 사용하여 그룹화하고 통계 정보를 얻을 수 있다.
- 예시: 4개 테이블을 JOIN한 후 CategoryID로 그룹화하여 각 카테고리별 첫 주문, 마지막 주문, 총 주문 수량 등을 계산할 수 있다.
- JOIN은 서브쿼리보다 더 빠르고 효율적으로 복잡한 계산을 수행할 수 있다.
31.2. SELF JOIN (같은 테이블 JOIN)
- 정의: 같은 테이블을 두 번 사용하여 마치 두 개의 다른 테이블인 것처럼 JOIN하는 방식이다.
- 필요성: 테이블 내에서 자기 자신과 관련된 데이터를 찾을 때 사용한다 (예: 직원 테이블에서 상사-부하 관계 찾기).
- 문법: SELECT ... FROM 테이블명 AS 별칭1 JOIN 테이블명 AS 별칭2 ON 별칭1.컬럼 = 별칭2.컬럼;
- 같은 테이블을 사용하므로 반드시 별칭을 부여하여 구분해야 한다.
- 예시: Employees 테이블을 e1, e2로 별칭을 부여하여 JOIN한다.
- SELECT e1.FirstName, e2.FirstName AS NextEmployee FROM Employees e1 JOIN Employees e2 ON e1.EmployeeID = e2.EmployeeID - 1;를 실행하면 각 직원과 그 다음 직원의 이름이 한 행에 출력된다.
- INNER JOIN의 한계: INNER JOIN은 양쪽 테이블에 모두 일치하는 데이터가 있을 때만 결과를 반환하므로, 첫 번째 직원(이전 직원이 없음)이나 마지막 직원(다음 직원이 없음)은 결과에서 제외된다.
31.3. OUTER JOIN (LEFT JOIN, RIGHT JOIN)
- 정의: INNER JOIN과 달리, 한쪽 테이블에 일치하는 데이터가 없어도 다른 쪽 테이블의 데이터를 모두 가져오는 방식이다.
- LEFT JOIN (또는 LEFT OUTER JOIN):
- 왼쪽 테이블의 모든 행을 가져오고, 오른쪽 테이블에서 일치하는 행이 있으면 결합한다. 일치하는 행이 없으면 오른쪽 테이블의 컬럼은 NULL로 채워진다.
- 예시: SELECT e1.FirstName, e2.FirstName AS NextEmployee FROM Employees e1 LEFT JOIN Employees e2 ON e1.EmployeeID = e2.EmployeeID - 1;를 실행하면 모든 직원과 그 다음 직원의 이름이 출력되며, 마지막 직원의 NextEmployee는 NULL이 된다.
- OUTER 키워드는 생략 가능하다.
- RIGHT JOIN (또는 RIGHT OUTER JOIN):
- 오른쪽 테이블의 모든 행을 가져오고, 왼쪽 테이블에서 일치하는 행이 있으면 결합한다. 일치하는 행이 없으면 왼쪽 테이블의 컬럼은 NULL로 채워진다.
- 예시: SELECT e1.FirstName, e2.FirstName AS PreviousEmployee FROM Employees e1 RIGHT JOIN Employees e2 ON e1.EmployeeID = e2.EmployeeID + 1;를 실행하면 모든 직원과 그 이전 직원의 이름이 출력되며, 첫 번째 직원의 PreviousEmployee는 NULL이 된다.
- NULL 값 처리 (IFNULL): LEFT JOIN이나 RIGHT JOIN으로 인해 발생하는 NULL 값을 IFNULL 함수를 사용하여 다른 값으로 대체할 수 있다.
- 예시: SELECT e1.FirstName, IFNULL(e2.FirstName, '없음') AS NextEmployee FROM Employees e1 LEFT JOIN Employees e2 ON e1.EmployeeID = e2.EmployeeID - 1;를 실행하면 다음 직원이 없는 경우 '없음'이 출력된다.
- 활용:
- Customers와 Suppliers 테이블을 LEFT JOIN하여 공급자가 없는 고객을 찾거나, RIGHT JOIN하여 고객을 구하지 못한 공급자를 찾을 수 있다.
31.4. CROSS JOIN (모든 조합 결합)

- 정의: 두 테이블의 모든 행을 가능한 모든 조합으로 결합한다. ON 절이나 WHERE 절과 같은 조건 없이 단순히 모든 조합을 생성한다.
- 결과 행 수: 테이블1의 행 수 * 테이블2의 행 수가 된다.
- 예시: Employees 테이블을 e1, e2로 SELF JOIN하면서 CROSS JOIN을 사용한다.
- SELECT e1.LastName, e2.FirstName FROM Employees e1 CROSS JOIN Employees e2;를 실행하면 모든 직원의 성과 모든 직원의 이름이 가능한 모든 조합으로 출력된다.
- 활용: 실제 사용 사례는 많지 않지만, 모든 가능한 조합을 확인해야 할 때 사용될 수 있다.
32. UNION (테이블 합치기)
32.1. UNION 기본 사용법
- 정의: 서로 다른 SELECT 문의 결과를 위아래로 합쳐서 하나의 결과 집합으로 만든다. JOIN이 테이블을 좌우로 연결하는 것과 다르다.
- 문법: SELECT 컬럼1, 컬럼2 FROM 테이블1 UNION SELECT 컬럼1, 컬럼2 FROM 테이블2;
- 각 SELECT 문의 컬럼 개수와 자료형이 일치해야 한다.
- 예시: Customers 테이블의 CustomerName, Country, City와 Suppliers 테이블의 SupplierName, Country, City를 UNION으로 합친다.
- SELECT CustomerName AS Name, Country, City, 'Customer' AS Type FROM Customers UNION SELECT SupplierName AS Name, Country, City, 'Supplier' AS Type FROM Suppliers ORDER BY Name;
- 결과: Name, Country, City 컬럼으로 합쳐진 고객과 공급자 목록이 출력되며, Type 컬럼으로 각 데이터의 출처를 구분할 수 있다.
32.2. 합집합 (UNION, UNION ALL)
- UNION: 두 SELECT 문의 결과를 합치고, 중복된 행은 제거한다.
- 예시: SELECT ID FROM Categories WHERE ID > 4 UNION SELECT ID FROM Employees WHERE ID % 2 = 0;를 실행하면 CategoryID가 4보다 큰 값(5, 6, 7, 8)과 EmployeeID가 짝수인 값(2, 4, 6, 8)을 합치고 중복된 값(6, 8)은 한 번만 출력된다.
- UNION ALL: 두 SELECT 문의 결과를 합치고, 중복된 행도 모두 포함하여 출력한다.
- 예시: SELECT ID FROM Categories WHERE ID > 4 UNION ALL SELECT ID FROM Employees WHERE ID % 2 = 0;를 실행하면 중복된 값(6, 8)이 두 번씩 출력된다.
32.3. 교집합 (INTERSECT)
- 정의: 두 SELECT 문의 결과 중 공통된 행만 가져온다. MySQL에는 INTERSECT 키워드가 없으므로 JOIN이나 IN 서브쿼리를 활용하여 구현한다.
- 구현 방법:
- SELECT c.ID FROM Categories c JOIN Employees e ON c.ID = e.ID WHERE c.ID > 4 AND e.ID % 2 = 0;를 실행하면 CategoryID가 4보다 크고 EmployeeID가 짝수인 값들 중 공통된 값(6, 8)만 출력된다.
32.4. 차집합 (EXCEPT)
- 정의: 첫 번째 SELECT 문의 결과 중 두 번째 SELECT 문의 결과에 없는 행만 가져온다. MySQL에는 EXCEPT 키워드가 없으므로 NOT IN 서브쿼리를 활용하여 구현한다.
- 구현 방법:
- SELECT ID FROM Categories WHERE ID > 4 AND ID NOT IN (SELECT ID FROM Employees WHERE ID % 2 = 0);를 실행하면 CategoryID가 4보다 큰 값(5, 6, 7, 8) 중 EmployeeID가 짝수인 값(2, 4, 6, 8)에 없는 값(5, 7)만 출력된다.
32.5. 대칭 차집합 (Symmetric Difference)
- 정의: 두 SELECT 문의 결과 중 한쪽에만 존재하는 행들을 가져온다 (양쪽에 모두 존재하는 공통된 행은 제외).
- 구현 방법: UNION ALL로 모든 행을 합친 후, GROUP BY와 HAVING COUNT(*) = 1을 사용하여 중복되지 않는 행만 필터링한다.
- 예시: SELECT ID FROM (SELECT ID FROM Categories WHERE ID > 4 UNION ALL SELECT ID FROM Employees WHERE ID % 2 = 0) AS Temp GROUP BY ID HAVING COUNT(*) = 1;를 실행하면 5, 7, 2, 4가 출력된다.
- 서브쿼리 별칭: UNION ALL 결과를 서브쿼리로 사용할 때는 반드시 별칭(예: AS Temp)을 부여해야 한다.
33. MySQL 설치 및 워크벤치 사용법
33.1. MySQL 설치 (Windows/macOS)
- 다운로드: MySQL 공식 다운로드 사이트에서 MySQL Community Server를 다운로드한다.
- macOS: MySQL Community Server와 MySQL Workbench를 각각 따로 다운로드하여 설치해야 한다. 추가로 Sakila 데이터베이스도 다운로드해야 한다.
- Windows: MySQL Installer를 통해 통합 설치가 가능하다.
- 설치 과정에서 기본 설정을 유지하고 Next를 눌러 진행한다.
- 루트 계정의 패스워드를 설정한다 (예: 12345678).
- 설정 완료 후 Execute를 눌러 설치를 마무리한다.
33.2. MySQL Workbench 연결 설정
- 워크벤치 실행: 설치된 MySQL Workbench를 실행한다.
- 새 연결 추가: + 버튼을 눌러 새 MySQL 연결을 추가한다.
- 연결 정보 입력:
- Connection Name: 'My DB' 등으로 설정한다.
- Username: 'root' (기본값)
- Password: 설치 시 설정한 루트 계정 비밀번호를 입력한다 (예: 12345678).
- 연결 테스트: Test Connection을 눌러 연결이 성공하는지 확인한다.
- 연결 생성: OK를 눌러 연결을 생성한다.
- 접속: 생성된 연결을 더블클릭하여 MySQL 서버에 접속한다.
33.3. 스키마(데이터베이스) 생성 및 관리
- 스키마: MySQL Workbench의 왼쪽 패널에 'Schemas'가 표시된다. 스키마는 테이블이 모인 단위로, 하나의 데이터베이스라고 생각할 수 있다.
- 스키마 생성 (SQL 명령어):
- CREATE SCHEMA MyDatabase DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci; 명령어를 사용하여 스키마를 생성한다.
- Refresh 버튼을 누르면 새로 생성된 스키마를 확인할 수 있다.
- 스키마 생성 (GUI): Schemas 패널에서 오른쪽 클릭 후 Create Schema를 선택하여 GUI로 스키마를 생성할 수도 있다.
- 기본 문자셋 (CHARACTER SET):
- utf8mb4로 설정해야 한글, 한자, 일본어, 이모티콘 등 전 세계 문자를 제대로 사용할 수 있다.
- latin1이나 ascii 같은 문자셋은 한글을 지원하지 않는다.
- 정렬 방식 (COLLATION):
- utf8mb4_general_ci는 대소문자를 구분하지 않는 일반적인 정렬 방식이다.
- 속도가 빠르며, 한국어 사용에 무리가 없다.
- 스키마 삭제: DROP DATABASE 스키마명; 명령어를 사용하거나 GUI에서 오른쪽 클릭하여 삭제할 수 있다.
33.4. Sakila 샘플 데이터베이스 설치
- 다운로드: Sakila 데이터베이스의 ZIP 파일을 다운로드한다.
- 압축 해제: 다운로드한 파일을 압축 해제한다.
- 스키마 생성: MySQL Workbench에서 File -> Open SQL Script를 통해 sakila-schema.sql 파일을 열고 실행하여 스키마를 생성한다.
- 이 스크립트는 스키마 생성 및 테이블 정의 명령어를 포함한다.
- 데이터 삽입: File -> Open SQL Script를 통해 sakila-data.sql 파일을 열고 실행하여 데이터를 삽입한다.
- 데이터 확인: sakila 스키마를 더블클릭하여 활성화한 후, 테이블을 열어 데이터가 성공적으로 삽입되었는지 확인한다.
- SQL 명령어 실행: sakila 스키마를 활성화한 상태에서 SELECT * FROM actor;와 같은 SQL 명령어를 실행하여 데이터를 조회할 수 있다.
- 테이블 관계 확인: Sakila 데이터베이스의 테이블들은 서로 관계를 맺고 있으므로, JOIN 등을 활용하여 데이터를 조회해 볼 수 있다.
- 예시: SELECT f.title, a.first_name, a.last_name FROM film f JOIN film_actor fa ON f.film_id = fa.film_id JOIN actor a ON fa.actor_id = a.actor_id;를 실행하면 영화 제목과 배우 이름이 함께 출력된다.
33.5. MySQL 서버와 클라이언트 툴의 이해

- MySQL 서버: 실제 데이터베이스 본 프로그램이다.
- MySQL Workbench: MySQL 서버에 접속하여 데이터를 시각적으로 관리할 수 있도록 돕는 클라이언트 툴이다.
- 버튼, UI 등을 통해 일반적인 프로그램처럼 쉽게 사용할 수 있다.
- 커맨드라인 인터페이스 (CLI):
- Windows에서는 PowerShell, macOS에서는 터미널을 통해 MySQL 서버에 직접 접속하여 SQL 명령어를 실행할 수 있다.
- mysql -u root -p 명령어를 입력하고 비밀번호를 입력하면 MySQL CLI에 접속할 수 있다.
- SHOW DATABASES;, USE sakila;, SELECT * FROM actor; 등의 명령어를 실행하여 데이터를 조회할 수 있다.
- 실제 프로그래머들은 CLI를 사용하기도 하지만, Workbench와 같은 GUI 툴을 사용하면 더 쉽고 간편하며 오류 소지도 줄일 수 있다.
34. 테이블 생성 및 데이터 입력
34.1. 테이블 생성 (CREATE TABLE)
- 문법: CREATE TABLE 테이블명 (컬럼명 자료형, ...);
- 테이블 이름과 각 컬럼의 이름, 그리고 해당 컬럼에 저장될 데이터의 자료형을 지정한다.
- 자료형 예시:
- INTEGER: 정수형 (예: ID)
- VARCHAR(길이): 가변 길이 문자열 (예: 이름, 최대 10글자)
- TINYINT: 작은 정수형 (예: 나이, 104까지)
- DATE: 날짜형 (예: 생일)
- 실습: MySQL Workbench에서 사용할 스키마를 더블클릭하여 활성화한 후, SQL 에디터에 CREATE TABLE 명령어를 입력하고 실행한다.
- Refresh 버튼을 누르면 새로 생성된 테이블을 확인할 수 있다.
- GUI를 통한 테이블 생성: MySQL Workbench에서 오른쪽 클릭 후 Create Table을 선택하여 GUI로 테이블을 생성할 수도 있다.
- GUI로 설정하면 APPLY 버튼 클릭 시 자동으로 SQL 명령어가 생성된다.
34.2. 테이블 변경 (ALTER TABLE)
- 문법: ALTER TABLE 테이블명 ...;
- 테이블 이름 변경: ALTER TABLE 기존테이블명 RENAME TO 새테이블명;
- 컬럼 변경: ALTER TABLE 테이블명 CHANGE COLUMN 기존컬럼명 새컬럼명 자료형;
- 컬럼 이름과 자료형을 동시에 변경할 수 있다.
- 컬럼 삭제: ALTER TABLE 테이블명 DROP COLUMN 컬럼명;
- 컬럼 추가: ALTER TABLE 테이블명 ADD COLUMN 컬럼명 자료형;
- 실습: ALTER TABLE 명령어를 입력하고 실행하여 테이블 이름, 컬럼 이름, 자료형 등을 변경할 수 있다.
- GUI를 통한 테이블 변경: MySQL Workbench에서 테이블을 오른쪽 클릭 후 Alter Table을 선택하여 GUI로 변경할 수도 있다.
34.3. 테이블 삭제 (DROP TABLE)
- 문법: DROP TABLE 테이블명;
- 실습: DROP TABLE 명령어를 실행하여 테이블을 삭제하거나, GUI에서 오른쪽 클릭하여 삭제할 수 있다.
34.4. 데이터 입력 (INSERT INTO)
- 문법 (모든 컬럼 입력): INSERT INTO 테이블명 VALUES (값1, 값2, ...);
- 테이블의 모든 컬럼에 데이터를 넣을 때는 컬럼명을 명시하지 않아도 된다.
- 값의 순서는 테이블 생성 시 정의된 컬럼 순서와 일치해야 한다.
- 문법 (특정 컬럼 입력): INSERT INTO 테이블명 (컬럼명1, 컬럼명2, ...) VALUES (값1, 값2, ...);
- 일부 컬럼에만 데이터를 넣을 때는 컬럼명을 명시해야 한다.
- 명시된 컬럼 순서와 값의 순서가 일치해야 한다.
- 자료형 일치: 입력하는 데이터의 자료형은 해당 컬럼의 자료형과 일치해야 한다.
- 예시: AGE 컬럼이 숫자형인데 문자열을 넣으려고 하면 오류가 발생한다.
- 여러 행 한꺼번에 입력: INSERT INTO 테이블명 (컬럼명1, ...) VALUES (값1, ...), (값2, ...), ...;
- 쉼표(,)로 구분하여 여러 개의 VALUES 괄호를 나열하면 여러 행을 한 번에 입력할 수 있다.
35. 테이블 제약 조건 (Constraints)
35.1. 제약 조건의 종류
- AUTO_INCREMENT: 숫자형 컬럼에 자동으로 1씩 증가하는 값을 부여한다.
- 값을 직접 입력하지 않아도 테이블에 데이터가 추가될 때마다 자동으로 값이 증가한다.
- PRIMARY KEY (기본 키):
- 테이블의 각 행을 고유하게 식별할 수 있는 컬럼에 설정한다.
- 특징: NULL 값을 허용하지 않으며, 중복된 값을 입력할 수 없다.
- 활용: AUTO_INCREMENT와 함께 사용하여 각 행에 고유한 식별자를 부여한다.
- 인덱싱: PRIMARY KEY로 지정된 컬럼은 자동으로 인덱싱되어 데이터 검색 속도가 빨라진다.
- NOT NULL: 해당 컬럼에 NULL 값을 입력할 수 없도록 한다.
- UNIQUE: 해당 컬럼에 중복된 값을 입력할 수 없도록 한다.
- PRIMARY KEY와 유사하지만, NULL 값을 허용한다.
- UNIQUE와 NOT NULL을 함께 사용하면 PRIMARY KEY와 동일한 특성을 갖는다.
- UNSIGNED: 숫자형 컬럼에 음수 값을 허용하지 않고 양수만 저장하도록 한다.
- 예시: 나이(AGE) 컬럼에 -3과 같은 음수 값이 들어가지 않도록 한다.
- DEFAULT 값: 컬럼에 값을 명시적으로 입력하지 않았을 때 자동으로 지정된 기본값을 넣는다.
- NULL 값이 아닌 특정 값을 기본으로 설정할 수 있다.
35.2. 제약 조건 적용 실습
- 테이블 생성 시 제약 조건 적용: CREATE TABLE 문에서 컬럼 정의 뒤에 제약 조건을 함께 명시한다.
- 예시: PersonID INT AUTO_INCREMENT PRIMARY KEY, FirstName VARCHAR(255) NOT NULL, Nickname VARCHAR(255) UNIQUE NOT NULL, Age TINYINT UNSIGNED DEFAULT 0, IsMarried TINYINT DEFAULT 0;
- 데이터 입력 시 제약 조건 확인:
- AUTO_INCREMENT 컬럼에는 값을 직접 입력하지 않는다.
- NOT NULL 컬럼에 NULL을 입력하거나, UNSIGNED 컬럼에 음수를 입력하면 오류가 발생한다.
- UNIQUE 컬럼에 중복된 값을 입력하면 오류가 발생한다.
- 제약 조건의 중요성: 제약 조건은 테이블에 잘못된 값이 들어가거나 서비스에 오류가 생기는 것을 방지하는 안전장치 역할을 한다.
36. MySQL 자료형 (Data Types)
36.1. 자료형의 개념
- 정의: 컴퓨터가 데이터를 0과 1로 인식할 때, 해당 데이터가 글자인지, 숫자인지, 시간 정보인지 등을 명시하여 컴퓨터가 올바르게 데이터를 읽고 처리할 수 있도록 하는 개념이다.
- 필요성:
- 컴퓨터는 0과 1의 조합을 어떻게 해석해야 할지 자료형이 없으면 알 수 없다.
- 테이블의 각 컬럼에는 명확히 자료형이 정해져 있어야 사람의 실수로 인한 오류를 방지할 수 있다.
36.2. 숫자 자료형

- 분류: 크게 정수(소수점 없음)와 실수(소수점 있음)로 나뉜다.
- 정수 자료형:
- 종류: TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT 등 크기별로 다양하다.
- 데이터 크기: 각 자료형은 표현할 수 있는 숫자의 범위(데이터 크기)가 다르다.
- 적절한 크기의 자료형을 선택해야 데이터 저장 공간 낭비를 막을 수 있다.
- SIGNED vs UNSIGNED:
- SIGNED: 양수와 음수를 모두 표현한다.
- UNSIGNED: 양수만 표현하며, SIGNED보다 양수 범위가 두 배 넓다.
- 실수 자료형:
- 고정 소수점 (DECIMAL):
- 표현할 수 있는 수의 범위는 좁지만, 값을 정확하게 표현한다.
- 정확한 계산이 필요한 금융 데이터 등에 사용된다.
- 부동 소수점 (FLOAT, DOUBLE):
- 넓은 범위의 수를 표현할 수 있지만, 컴퓨터 특성상 값의 정확도에 오차가 발생할 수 있다.
- 정확도보다 넓은 범위가 중요할 때 사용된다.
- 고정 소수점 (DECIMAL):
36.3. 문자 자료형
- CHAR(길이): 고정 길이 문자열.
- 지정된 길이만큼 항상 공간을 차지한다 (짧은 문자열도 공백으로 채워진다).
- 검색 속도가 빠르다.
- VARCHAR(길이): 가변 길이 문자열.
- 실제 저장된 문자열의 길이만큼만 공간을 차지한다 (추가로 1바이트의 길이 정보 저장).
- 저장 공간 효율성이 좋다.
- CHAR vs VARCHAR 선택 기준:
- 고정 길이 문자열: 항상 같은 길이의 문자열이 들어갈 경우 CHAR가 더 효율적이다 (예: 우편번호, 전화번호).
- 가변 길이 문자열: 길이가 가변적인 문자열이 들어갈 경우 VARCHAR가 더 효율적이다 (예: 이름, 주소).
- TEXT: 긴 문자열 (장문) 저장.
- 게시판 글, 긴 설명 등 수백 글자 이상의 장문 데이터에 사용된다.
- TINYTEXT, TEXT, MEDIUMTEXT, LONGTEXT 등 크기별로 다양하다.
36.4. 시간 자료형
- DATE: 날짜 정보 (YYYY-MM-DD) 저장.
- TIME: 시간 정보 (HH:MM:SS) 저장.
- DATETIME: 날짜 및 시간 정보 (YYYY-MM-DD HH:MM:SS) 저장.
- 시간 데이터를 그 자체로 저장한다 (글자로 써놓는 것과 유사).
- 어떤 시간대에서 읽든 동일한 값을 반환한다.
- TIMESTAMP: 날짜 및 시간 정보 (YYYY-MM-DD HH:MM:SS) 저장.
- 내부적으로는 UTC(협정 세계시) 기준으로 숫자 값을 저장한다.
- 데이터베이스 서버의 시간대에 따라 다르게 읽힐 수 있다 (시간대 변환).
- 게시판 글 작성 시간 등 시간대 변환이 필요한 경우에 사용된다.
- 선택 기준:
- DATETIME: 역사적 기록 등 시간 데이터를 가감 없이 기록할 때.
- TIMESTAMP: 게시판 댓글 시간 등 시간대 변환이 필요한 경우.
37. 예제 테이블 생성 및 샘플 데이터 삽입
37.1. 섹션(구역) 테이블 생성
- sections 테이블:
- id: INT AUTO_INCREMENT PRIMARY KEY (자동 증가 기본 키)
- name: CHAR(10) NOT NULL (고정 길이 문자열, 10자, NULL 불가)
- floor: TINYINT UNSIGNED NOT NULL (작은 양의 정수, NULL 불가)
- 데이터 삽입: INSERT INTO sections (name, floor) VALUES ('한식', 1), ('중식', 2), ('일식', 1), ('양식', 2), ('분식', 1);
- 실습: MySQL Workbench에서 해당 SQL 명령어를 실행하여 테이블을 생성하고 데이터를 삽입한다.
37.2. 비즈니스(식당) 테이블 생성
- businesses 테이블:
- id: INT AUTO_INCREMENT PRIMARY KEY
- section_id: INT NOT NULL (섹션 테이블의 외래 키)
- FOREIGN KEY (section_id) REFERENCES sections(id): sections 테이블의 id를 참조하는 외래 키 설정.
- name: VARCHAR(50) NOT NULL (가변 길이 문자열, 50자, NULL 불가)
- status: CHAR(10) DEFAULT 'Open' (고정 길이 문자열, 10자, 기본값 'Open')
- takeout_available: TINYINT DEFAULT 1 (작은 정수, 기본값 1)
- 데이터 삽입: INSERT INTO businesses (section_id, name, status, takeout_available) VALUES (1, '전통한정식', 'Open', 1), (2, '만리장성', 'Open', 1), ...;
- 실습: MySQL Workbench에서 해당 SQL 명령어를 실행하여 테이블을 생성하고 데이터를 삽입한다.
37.3. 메뉴 테이블 생성
- menus 테이블:
- id: INT AUTO_INCREMENT PRIMARY KEY
- business_id: INT NOT NULL (비즈니스 테이블의 외래 키)
- FOREIGN KEY (business_id) REFERENCES businesses(id)
- name: VARCHAR(50) NOT NULL
- kcal: DECIMAL(7,2) (총 7자리, 소수점 이하 2자리 실수)
- price: INT NOT NULL
- 데이터 삽입: INSERT INTO menus (business_id, name, kcal, price) VALUES (1, '물냉면', 350.50, 11000), (1, '비빔냉면', 380.00, 11000), ...;
- 실습: MySQL Workbench에서 해당 SQL 명령어를 실행하여 테이블을 생성하고 데이터를 삽입한다.
37.4. 평점 테이블 생성
- ratings 테이블:
- id: INT AUTO_INCREMENT PRIMARY KEY
- business_id: INT NOT NULL (비즈니스 테이블의 외래 키)
- FOREIGN KEY (business_id) REFERENCES businesses(id)
- star_rating: TINYINT UNSIGNED NOT NULL (1~5점)
- comment: VARCHAR(255)
- created_at: TIMESTAMP DEFAULT CURRENT_TIMESTAMP (기본값으로 현재 시간 자동 입력)
- 데이터 삽입: INSERT INTO ratings (business_id, star_rating, comment) VALUES (1, 5, '정말 맛있어요!'), (1, 4, '깔끔하고 좋아요.'), ...;
- 실습: MySQL Workbench에서 해당 SQL 명령어를 실행하여 테이블을 생성하고 데이터를 삽입한다.
- 활용: 생성된 예제 테이블들을 JOIN 등을 활용하여 다양하게 조회하고 분석해 볼 수 있다.
38. 데이터 변경 및 삭제
38.1. 데이터 삭제 (DELETE FROM)
- MySQL Workbench 설정: Edit -> Preferences -> SQL Editor에서 Safe Updates 옵션의 체크를 해제해야 WHERE 절 없이 DELETE 문을 실행할 수 있다. (안전장치 해제)
- 문법: DELETE FROM 테이블명 WHERE 조건;
- WHERE 절로 조건을 지정하여 특정 행만 삭제한다.
- 예시: DELETE FROM businesses WHERE status = 'Closed';를 실행하면 status가 'Closed'인 식당만 삭제된다.
- GUI를 통한 삭제: MySQL Workbench에서 테이블 내용을 조회한 후, 특정 행을 선택하고 Delete 버튼을 눌러 삭제할 수도 있다.
- 주의: WHERE 절 없이 DELETE FROM 테이블명;을 실행하면 테이블의 모든 행이 삭제된다.
- DELETE로 삭제된 경우, AUTO_INCREMENT 값은 마지막으로 사용된 값에 이어서 증가한다.
38.2. 테이블 초기화 (TRUNCATE TABLE)
- 문법: TRUNCATE TABLE 테이블명;
- 특징: DELETE와 달리 테이블의 모든 행을 삭제하고, AUTO_INCREMENT 값을 1부터 다시 시작하도록 테이블 자체를 초기화한다.
- 예시: TRUNCATE TABLE businesses; 실행 후 데이터를 다시 삽입하면 id가 1부터 시작한다.
38.3. 데이터 수정 (UPDATE)
- 문법: UPDATE 테이블명 SET 컬럼1 = 새값1, 컬럼2 = 새값2, ... WHERE 조건;
- SET 절에 수정할 컬럼과 새로운 값을 지정한다.
- WHERE 절로 조건을 지정하여 특정 행만 수정한다.
- 단일 컬럼 수정:
- 예시: UPDATE menus SET name = '삼선짜장' WHERE id = 12;를 실행하면 id가 12인 메뉴의 이름이 '삼선짜장'으로 변경된다.
- 여러 컬럼 동시 수정:
- 예시: UPDATE menus SET name = '열정도 떡볶이', kcal = 700, price = 5000 WHERE business_id = 4 AND name = '국물 떡볶이';를 실행하면 business_id가 4인 식당의 '국물 떡볶이' 메뉴의 이름, 칼로리, 가격이 한꺼번에 변경된다.
- 컬럼 데이터 활용 수정: 기존 컬럼의 값을 활용하여 새로운 값을 설정할 수 있다.
- 예시: UPDATE menus SET price = price + 1000 WHERE business_id = 2;를 실행하면 business_id가 2인 식당의 모든 메뉴 가격이 1000원씩 인상된다.
- 서브쿼리를 활용한 고급 수정: WHERE 절에 서브쿼리를 넣어 복잡한 조건으로 수정할 수 있다.
- 예시: UPDATE menus SET name = CONCAT('전통 ', name) WHERE business_id IN (SELECT id FROM businesses WHERE section_id = (SELECT id FROM sections WHERE name = '한식'));를 실행하면 '한식' 섹션에 속한 식당의 메뉴 이름 앞에 '전통 '이 붙는다.
- 주의: WHERE 절 없이 UPDATE 테이블명 SET 컬럼 = 값;을 실행하면 테이블의 모든 행이 변경된다.
- 예시: UPDATE menus SET name = '획일화된 메뉴';를 실행하면 모든 메뉴의 이름이 '획일화된 메뉴'로 변경된다.
왕초보용! MySQL 데이터베이스 강좌4~5장 바로가기
왕초보용! MySQL 데이터베이스 강좌4~5장 - 하나이프 블로그
이 콘텐츠는 MySQL의 심화 기능부터 실제 웹사이트 구축 및 배포까지 전 과정을 다루는 실용적인 가이드입니다. 기본키, 고유키, 외래키 제약과 같은 데이터베이스 설계의 핵심 개념부터, 뷰(Vi
hanaif.co.kr
반응형
'인터넷' 카테고리의 다른 글
| 백엔드 개발구조 - 백엔드입문 01화(개발편) (0) | 2025.09.12 |
|---|---|
| 스프링 강의 01 /프로젝트생성 /프레임워크 /설치 /다운로드 (1) | 2025.09.12 |
| 리액트 19버전 강의(3. JSX 기본 규칙) (0) | 2025.09.12 |
| 리액트 19버전 강의(2. 리액트 실행하기 with Vite, Node.js) (0) | 2025.09.12 |
| 리액트 19버전 강의(1. 리액트의 핵심 원리 단 하나) (0) | 2025.09.12 |